

目次
はじめに:AI開発の現場で起きている「2つの誤解」
昨今の生成AIブームにより、製造業や医療、流通の現場では「自社のデータを使って、独自のAIを作りたい」というニーズが爆発的に増えています。しかし、私が日々お客様と対話する中で、ある種の「混乱」を感じることが多くなりました。特に、NVIDIAの最新アーキテクチャ「NVIDIA Blackwell」を搭載した2つの製品、NVIDIA DGX Spark™とNVIDIA® Jetson AGX Thor™についてです。「どちらも高性能なAIコンピュータなら、性能が高い方を買えばいいのではないか?」「DGX Sparkの方がスペック高そうだから、これをロボットに載せたい」
——こうした声を頻繁に耳にします。しかし、この2つの製品は「どちらが上か」という比較対象ではありません。これらは「AIを作るための実験室(Lab)」と「AIを動かすための現場(Field)」という、全く異なる役割を持ったパートナー関係にあります。
▼図1 AI開発の現場で陥りがちな「2つの誤解」

本記事では、なぜこの2つの使い分けがAIプロジェクトの成否を分けるのか。カタログスペックだけでは見えてこない「設計思想の違い」と「エンジニアリングの壁」について、3つの視点から徹底的に解剖します。
1. NVIDIA DGX Spark について
1-1. デスクサイドに舞い降りた「1ペタフロップス」
かつて最先端のAIモデルを扱うには、巨大なデータセンターへのアクセスが必要でした。2016年、OpenAIがGPTシリーズの前身となるモデルを開発していた際、彼らが使用していたのはNVIDIA DGX-1というスーパーコンピュータでした。それから数年、AIモデルは巨大化の一途をたどっていますが、同時に「手元の環境で、セキュアに試したい」というニーズも切実になっています。ここで登場したのがNVIDIA DGX Sparkです。この製品は、推論・低精度演算(FP4)において、かつてのDGX-1クラスに迫るスループットをデスクサイズで実現し、わずか240W程度(※構成・負荷条件により変動、本体単体の目安であり、周辺機器は含まない)の消費電力で、デスクの上に置けるサイズに凝縮した「パーソナルAIスーパーコンピュータ」です。
さらに重要なのは「クラウドにデータを出さずにAI開発が完結する」という点です。製造図面、医療データ、顧客情報といった機密データを外部クラウドへ転送せず、社内・閉域環境で安全に学習・検証を回せるため、情報漏洩リスクやコンプライアンス対応の負担を大幅に低減できます。クラウド利用時に発生するデータ転送料、リージョン制約、社内セキュリティ審査といった"見えないコスト"を回避できる点も、DGX Sparkの大きな価値です。
結論:DGX Sparkは、データセンター級のAI演算能力を「デスクサイド」で安全に扱える、開発者向けのパーソナルAIスーパーコンピューターです。
1-2. DGX SparkとJetson Thor:決定的な「生まれ」の違い
なぜDGX Sparkが必要なのか。それを理解するには、Jetson Thorとの「生まれ(設計思想)」の違いを知る必要があります。・DGX Spark(ITの思想)
これは「開発者のためのマシン」です。目的はスループット(処理量)の最大化です。膨大なデータを読み込み、巨大なLLM(大規模言語モデル)をファインチューニングし、試行錯誤の回数を稼ぐことに特化しています。「ベストエフォート」で動くため、多少の遅延があっても全体の処理が速く終わることが正義とされています。
▼図2 DGX Sparkの特長

・Jetson Thor(OTの思想)
これは「現場のためのマシン」です。目的はレイテンシ(遅延)の保証と決定論的動作です。ロボットや医療機器に組み込まれるため、「必ず0.01秒以内に止まる」といったリアルタイム性が命です(※具体的な遅延保証値はOS構成や制御設計に依存します)。どんなに計算が速くても、時々止まるマシンは現場では使えません。
▼図3 Jetson Thorの特徴

つまり、DGX Sparkは「天才的な頭脳を持つ研究者」であり、Jetson Thorは「反射神経抜群の現場指揮官」なのです。
▼図4 DGX SparkとJetson Thorの違い

結論:DGX SparkとJetson Thorの違いは「性能」ではなく、「IT(探索・最適化)」と「OT(リアルタイム制御)」という設計思想の違いにあります。
2. 技術的な決定的違い
2-1. DGX Sparkはなぜ「128GB」が必要なのか? ~100GBの壁~
生成AI開発において、開発者が最も苦しむのが「VRAM(ビデオメモリ)不足」です。例えば、高性能なコンシューマー向けGPU(NVIDIA RTX™ 4090など)でもメモリは24GB。プロ向けのNVIDIA RTX™ 6000 Adaでも48GBです。しかし、実用的な大規模言語モデルであるGPT-OSS 120Bクラスを動かすには、量子化(FP4/INT4等)を前提とした場合で、約60GBのメモリが必要になります。
DGX Sparkは、CPUとGPUがシームレスにアクセスできる128GBの統合メモリ(LPDDR5x)を搭載しています。これにより、これまでは数千万円クラスのサーバーラックでしか扱えなかった巨大モデルを、手元のマシン1台にロードすることが可能になります。 OSやシステム領域を除いても、約100GB以上の広大なワークスペースが確保されており、これにより「メモリに乗らないから試せない」という開発の初期障壁を完全に破壊します。
さらに、ローカル環境で完結することで、デバッグや再現実験、チーム内での環境共有が容易になり、開発者体験そのものが大きく向上します。
統合メモリであることの価値は、単なる「容量の大きさ」だけではありません。CPUとGPU間でメモリコピーを意識する必要がなくなり、大規模RAG、マルチエージェント構成、巨大なベクトルデータベースを同時にメモリ上で扱えるようになります。
従来は「GPUメモリに収まらないから設計を諦める」必要があったアーキテクチャも、DGX Sparkでは最初から実装・検証できるため、設計の自由度そのものが大きく広がります。
結論:DGX Sparkの128GB統合メモリにより、モデルサイズやデータ容量を強く意識せずにAI設計・検証が行えるようになります。
2-2. DGX Spark vs Jetson Thor:技術的な決定的違い
ここからは、カタログスペックの裏側にある「制御設計」の違いについて深掘りします。なぜDGX Sparkを現場のロボットに載せてはいけないのか、その技術的理由です。
A. リアルタイム性とGPU分割:
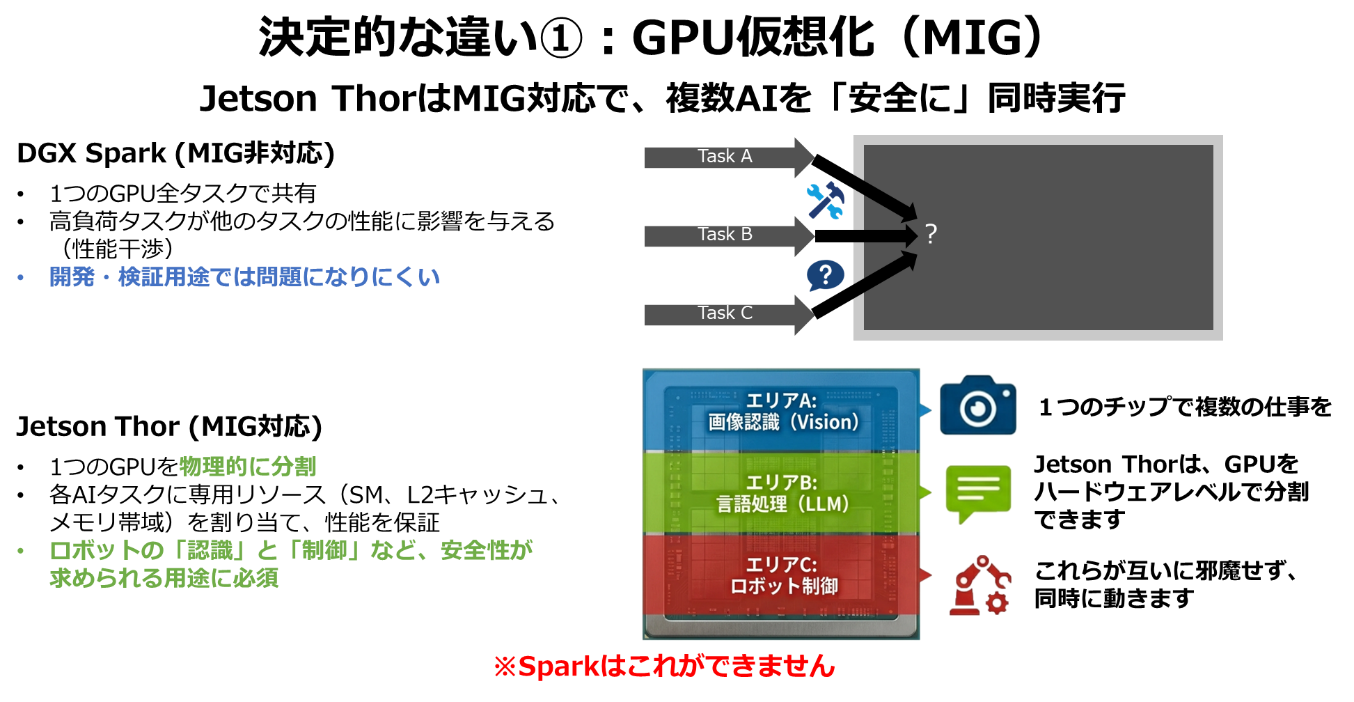
Jetson Thorは、Blackwell世代でも強化・対応している、MIG(Multi-Instance GPU)に対応しています。これは1つのGPUをGPU内部リソース単位で分割し、「カメラ処理用」「制御用」「LLM用」と専用レーンを割り当てる機能です。これにより、重いLLM処理が走っても、ロボットの姿勢制御が遅延して転倒するといった事故を防げます。対してDGX Sparkは、MIG非対応です。すべてのリソースを1つのタスクに集中させて学習を高速化する設計であり、ソフトウェア的な分離は可能ですが、ハードリアルタイム保証はできず、複数の処理が走るとお互いに干渉し合う可能性があります。
▼図5 GPUを分ける技術(MIG)の対応
▼図6 リアルタイム性の対応
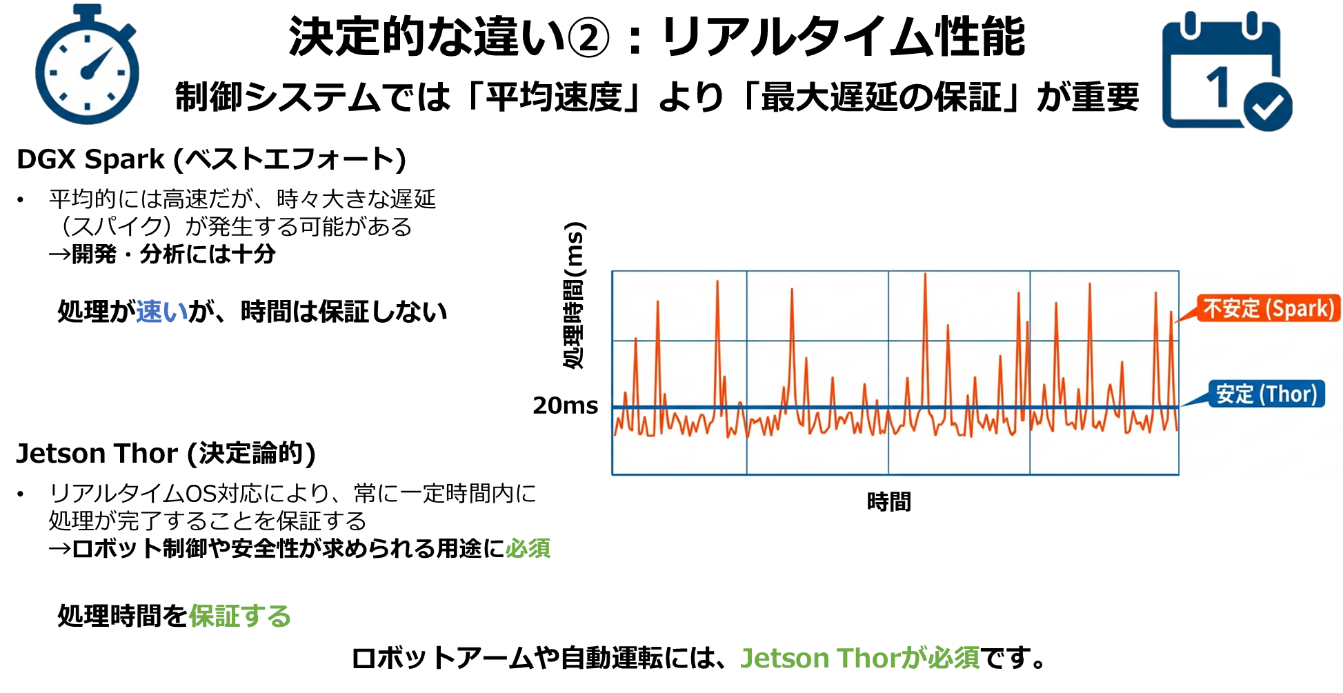
ただし、Jetson Thorはリアルタイム推論や現場制御には最適である一方、大規模モデルの学習・検証や高速な試行錯誤を行うには計算資源や開発自由度の面で制約があります。このギャップを埋める役割を担うのがDGX Sparkです。
B. 見落としがちな「I/Oと電源設計」の壁:
営業現場でよく頂く質問に、「DGX SparkにZEDカメラ(深度カメラ)を繋ぐと不安定になる」というものがあります。これは不具合ではなく、I/O(入出力)と電源設計の思想差によるものです。
▼図7 DGX SparkでZEDカメラを使うと切断される理由
・DGX Spark (IT機器):
サーバー/PC用途の設計です。USBポートはあくまでマウスやキーボード、一時的なストレージ用であり、産業用カメラのような大電力デバイスへの常時安定給電や、ミリ秒単位の通信保証は設計の主目的ではありません。高負荷なセンサーを接続すると、電圧降下や省電力機能の介入で認識が不安定になるリスクがあります。
▼図8 電源管理ロジックの違いについて
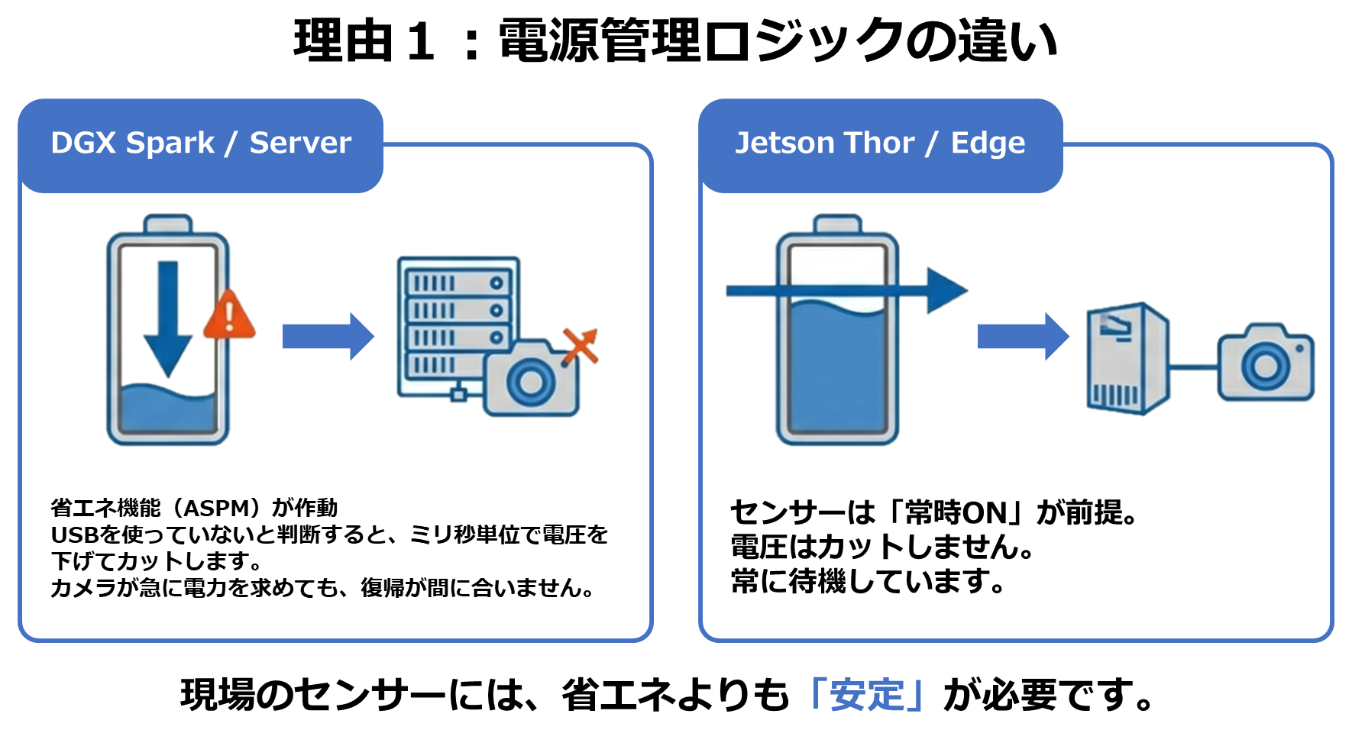
・Jetson Thor(産業機器):
ロボットの「眼」となるカメラやLiDARを直接接続することを前提に設計されています。USBだけでなく、より安定した産業用インターフェース(MIPI CSI)を備え、電源周りもセンサーへの安定供給を最優先に設計されています。
▼図9 規格の違いについて
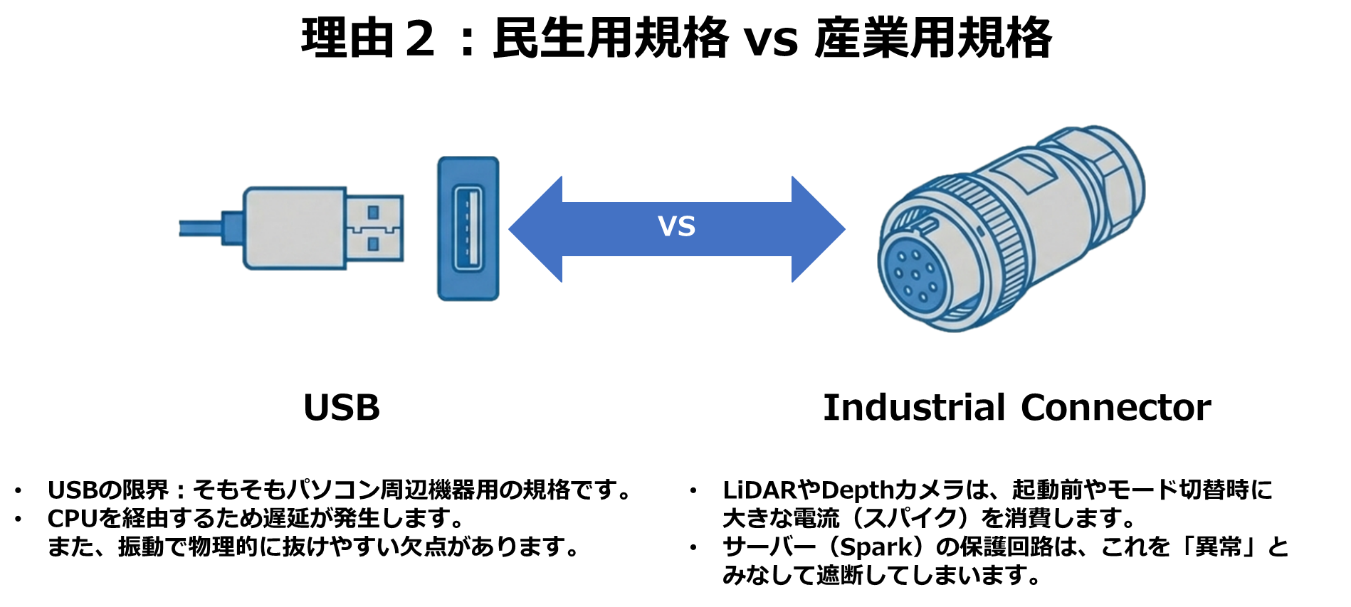
つまり、DGX Sparkは「計算する箱」であり、Jetson Thorは「外界とつながる箱」なのです。
C. タフネス:過酷な環境に耐える
DGX Sparkは、デスクサイドやオフィス、サーバールームのようなIT機器として整った環境で、AI開発や推論を進めるのが得意です。一方Jetson Thorは、ロボットやエッジ機器に組み込んで、現場の過酷さを織り込んだ運用を前提にしています。
まず温度です。工場の装置周りは熱がこもったり、屋外だと寒暖差が大きい場合があります。そのような環境では、一般的なサーバーは、冷却・防塵・設置条件を整えないと不安定になりがちです。
Jetson Thorは、エッジ用途として、産業向け筐体やパートナー製品と組み合わせることで、広い温度条件での運用を狙えるのがポイントです。
次に振動・衝撃です。配送ロボットやAGV、設備の近くは常に振動があります。PCサーバーは移動や衝撃を前提にしていないので、ストレージやコネクタ周りでトラブルが起きやすいです。
Jetson Thorは、そもそも「ロボットの頭脳」として、振動・衝撃がある場所でも止まりにくい設計・実装がしやすいという思想です。
最後に24時間365日です。現場は止めるコストが大きいので、連続稼働が基本になります。Jetson Thorは、現場機器に組み込んで “常時稼働のエッジAI”として使う前提なので、監視・保守の設計も含めて運用が組み立てやすいです。
要するに、DGX Sparkは、「開発・検証・高度な推論の拠点」、Jetson Thorは、「現場で動き続ける実行基盤」という役割分担になります。
▼図10 タフネスさの違い

3. ワークフローとユースケースについて
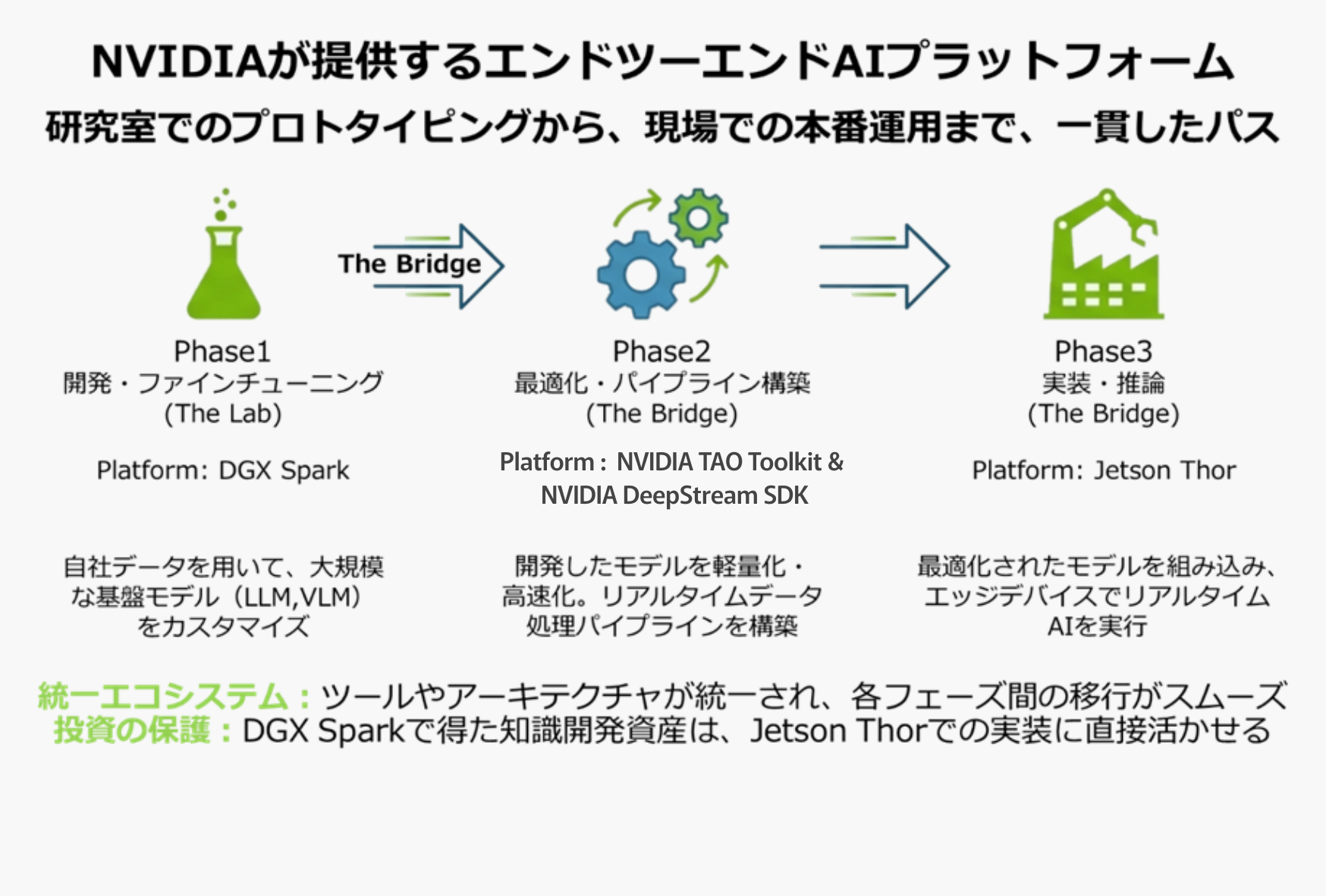
3-1. 開発(DGX Spark)と実装(Jetson Thor)をつなぐワークフロー
AI開発は、「モデルを作って終わり」ではありません。現場で動いて初めて価値を生みます。ここで重要になるのが、DGX SparkとJetson Thorを連携させたEnd-to-Endのワークフローです。Phase1:開発(The Lab)
セキュアなローカル環境で、社外秘のデータを使ってLLMや外観検査AIを学習させます。128GBメモリを活かし、複数のAIエージェント(コード生成、画像分析、司令塔など)を同時に立ち上げ、複雑なシステムのプロトタイプを作成します。
Phase2:最適化(The Bridge)
開発したモデルを、Jetson Thorで動くように軽量化・変換(TensorRT化)します。
Phase3:実装(The Field)
最適化されたモデルを現場のロボットや医療機器にデプロイし、推論を実行します。
この流れがスムーズなのは、両者が同じNVIDIAのソフトウェアスタック(CUDA®、NVIDIA DGX™ OS、JetPack)で動いているからです。クラウドとエッジの間にあった「言葉の壁」がなくなることで、開発期間を数ヶ月から数週間に短縮できます。
具体的には、以下のような“待ち時間”がほぼゼロになります。
- クラウドGPUの空き待ちや、利用申請・契約手続きの待ち時間が不要
- データ転送やアップロードにかかる時間・コストが発生しない
- 実験環境を壊してもすぐに再構築でき、試行回数を圧倒的に増やせる
- オフライン環境でも開発・検証が継続できる
例えば、初期PoCはDGX Spark1台から開始し、部門レベルの検証では2〜3台構成へ拡張、全社展開フェーズでは上位DGXやクラウド連携へ段階的に移行するといったスケール設計が現実的です。
▼図11 開発と実装をつなぐワークフロー
この共通基盤により、Dockerイメージ、推論パイプライン、CI/CD設定、MLOps設計といったソフトウェア資産をそのまま横展開でき、開発投資の再利用効率を大きく高めることができます。
結論:DGX Sparkで開発・検証したAIを、Jetson Thorへスムーズに展開することで、PoCから本番までのリードタイムを大幅に短縮できます。
3-2. 業種別ユースケース:適材適所の具体例
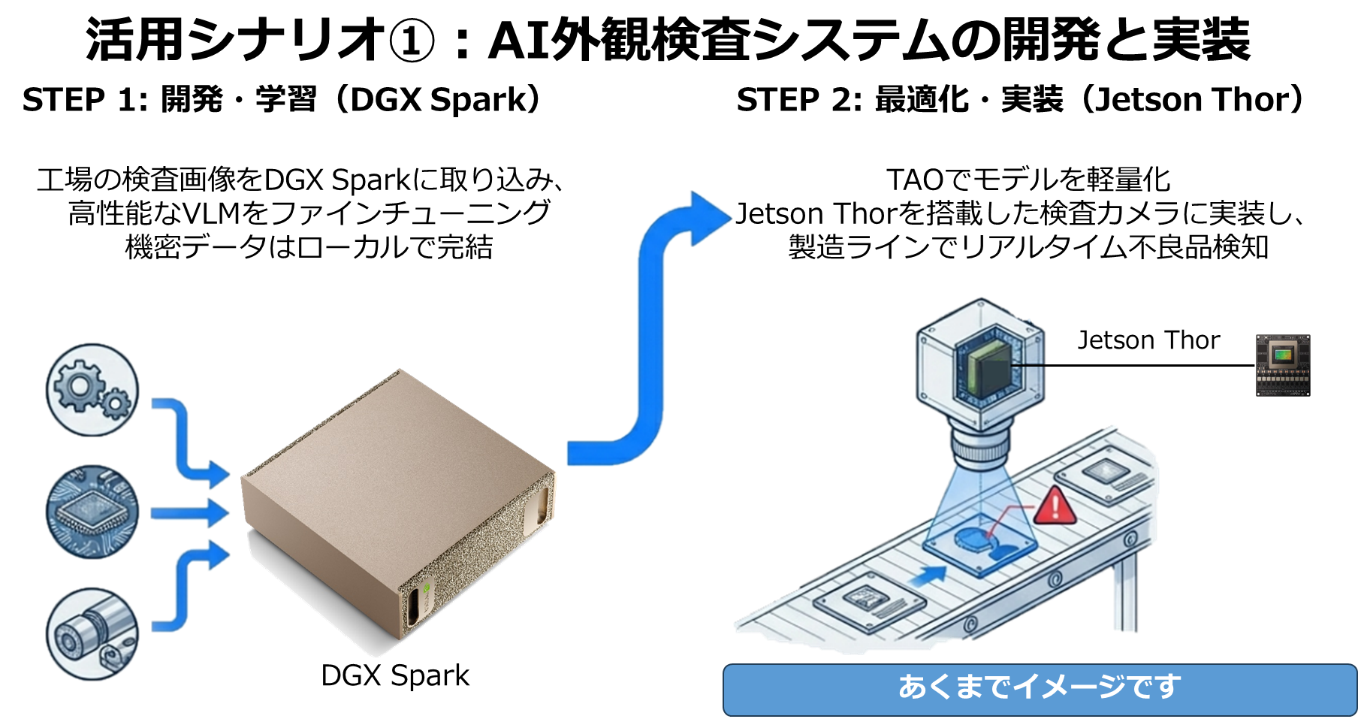
製造業:(外観検査と自律対応)
- 課題: 検査AIは作れても、「なぜ不良か」の解析やライン停止の判断が遅れる。
- DGX Spark(開発): 高解像度画像とセンサーログを読み込ませ、不良要因を特定する大規模なマルチモーダルモデルを学習・調整。
- Jetson Thor(実装): 完成したモデルを検査機に搭載。MIGを活用し、「検査」と「ライン制御」を(GPU内部リソースを論理的に)完全に分離して実行することで、AI推論中も制御を止めない安全なシステムを構築。
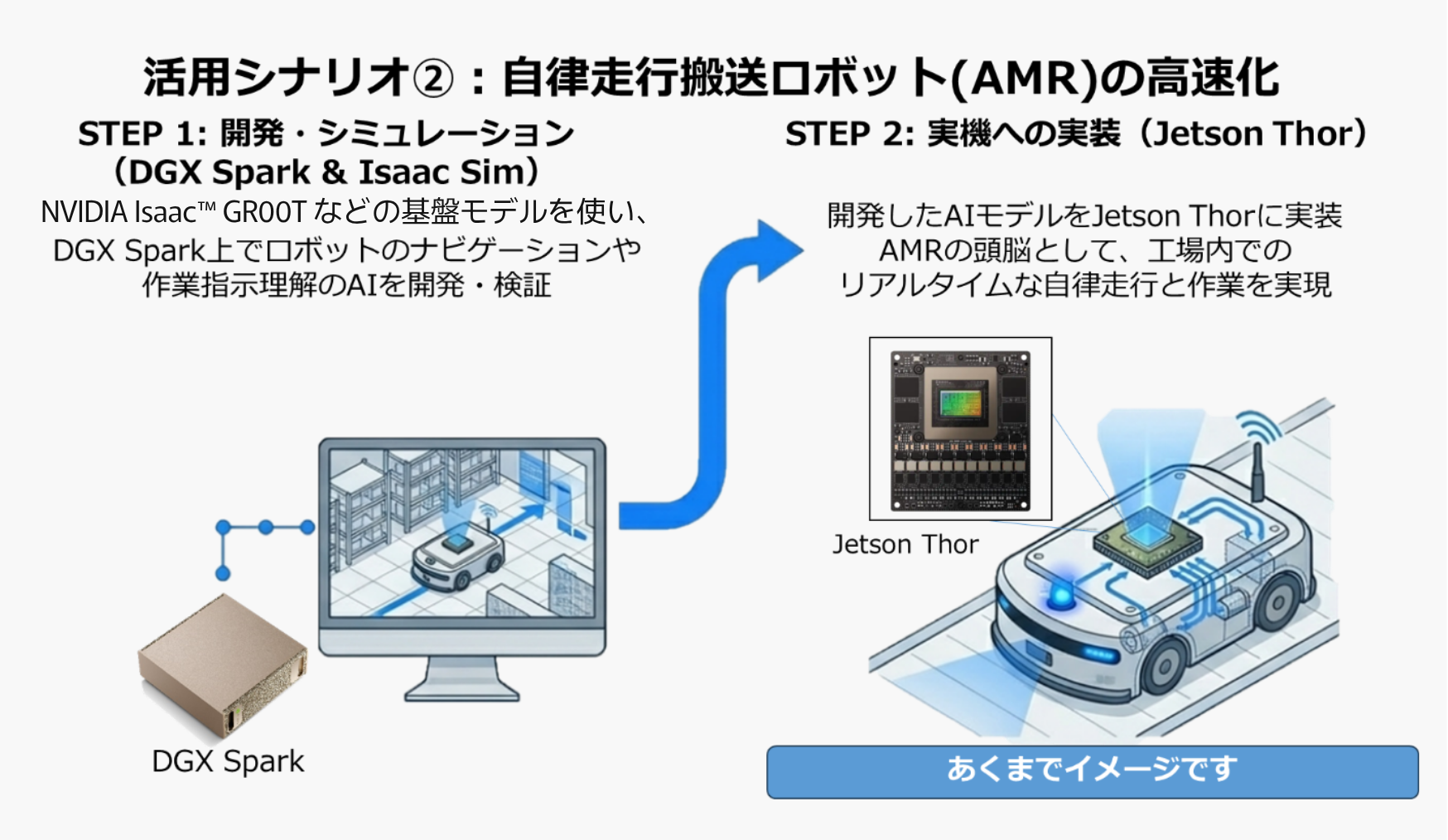
物流・流通:倉庫ロボット(AMR)の知能化
- 課題: 従来のロボットは決まったルートしか動けず、突発的な障害物に対応できない。
- DGX Spark(開発): 工場内のデジタルツイン(NVIDIA Isaac Sim™)上で、ロボットに数万回のシミュレーション走行をさせ、最適な経路計画AIを学習。
- Jetson Thor(実装): 学習済みAIをAMRに搭載。カメラ映像から人と障害物をリアルタイムに認識し、その場でルートを変更して回避行動をとる。ここではThorの低遅延性が事故防止の鍵となる。
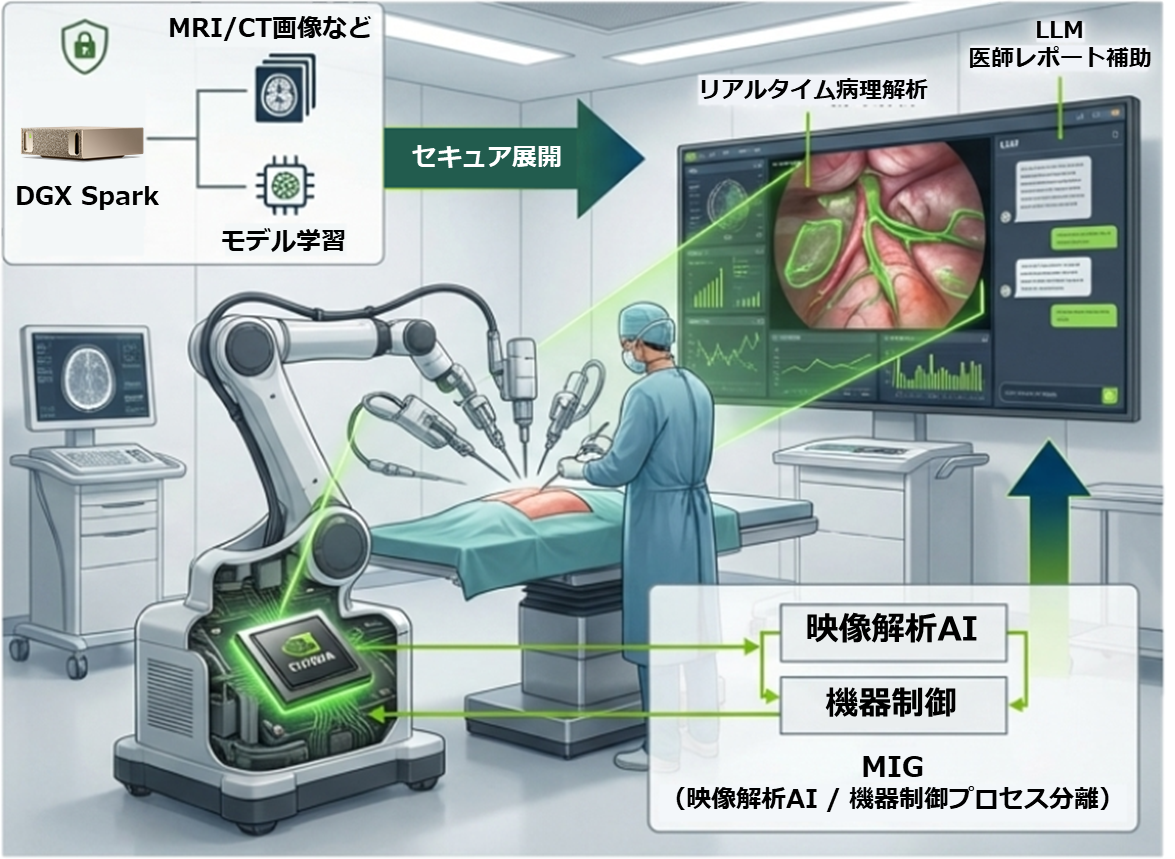
医療:手術支援と院内データ活用
- 課題: 手術支援ロボットには極低遅延が求められる一方、患者データの学習には高度なセキュリティが必要。
- DGX Spark(開発): 院内の閉じたネットワーク内で、膨大なMRI/CT画像やカルテ情報を学習させ、診断支援AIを作成。データが外部に出ないためセキュリティが担保される。
- Jetson Thor(実装): 手術ロボットに組み込み、術中の映像をリアルタイム解析して医師に血管の位置をガイド。命に関わるため、医療分野ではOSレベルでのリアルタイム保証(RTOSやリアルタイムLinux等)が求められるケースが多くなる。
4.まとめ:より良いソリューションのために
DGX SparkとJetson Thor。この2つは「競合」ではなく、野球の「ピッチャーとキャッチャー」、あるいは「設計室と工場」のような補完関係にあります。また、DGX Sparkを活用することで、PoCや検証フェーズの試行錯誤コストを抑えながら「早く失敗し、早く学習する」サイクルを回せる点も重要です。結果として、AI投資における経営リスクそのものを低減できます。・DGX Spark:「AIを作る場所」。巨大なメモリと計算力で、クラウドに頼らず、手元で何度でも実験と失敗を繰り返せる創造の拠点。
・Jetson Thor:「AIが働く場所」。リアルタイム性、安定性、センサー接続性を備え、開発された知能を物理世界で確実に実行する実行の拠点。コストの観点でも、この役割分担は非常に合理的です。クラウドGPUを長期間占有すると、利用料金に加え、データ転送料、セキュリティ監査、ネットワーク設計などの付帯コストが積み上がります。
DGX Sparkを社内に設置することで、PoCや検証フェーズの計算資源を“固定資産化”でき、試行回数が増えても追加コストはほぼ発生しません。結果として、長期的なTCO(総保有コスト)を大きく抑えながら、開発スピードを最大化できます。
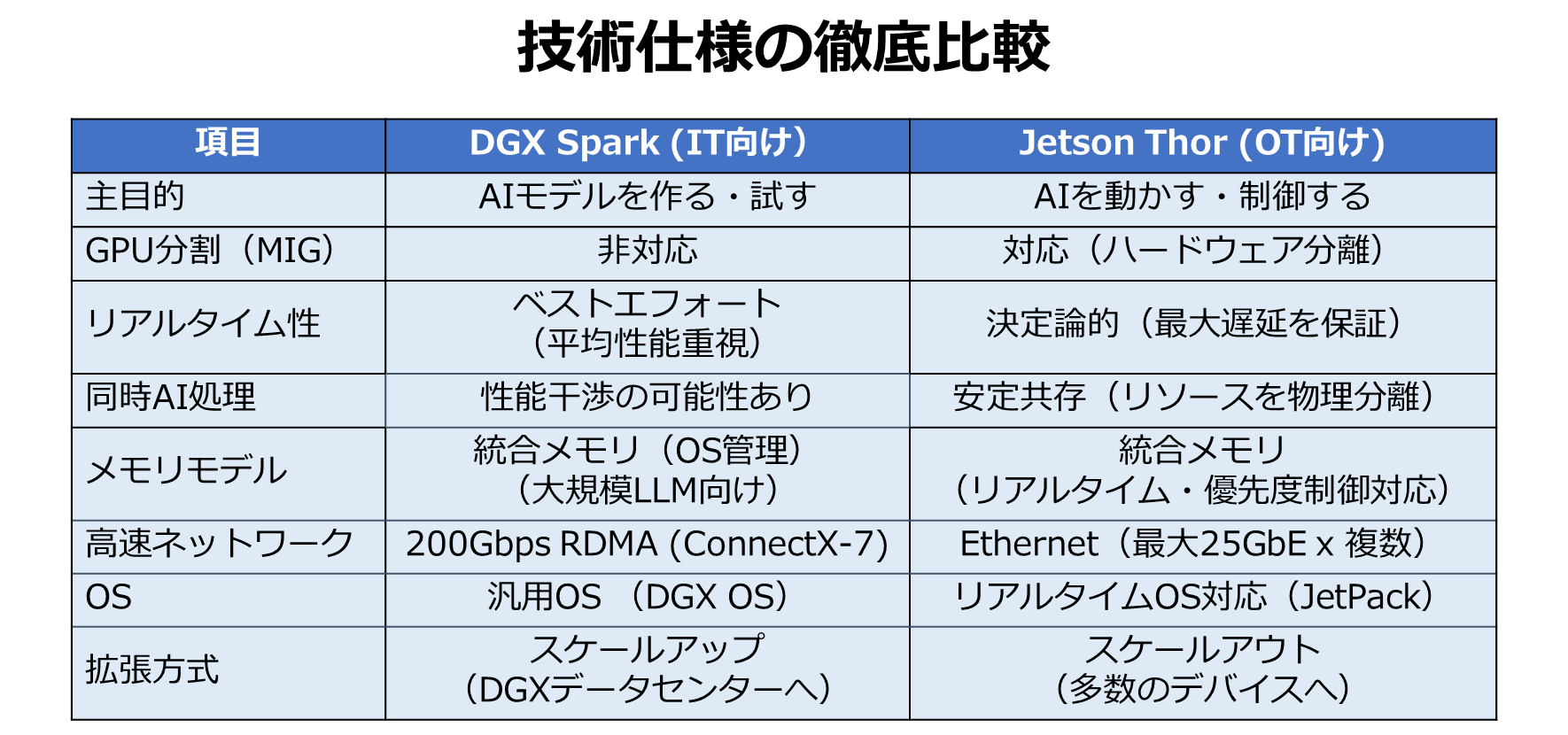
▼図15 技術仕様の徹底比較
【想定される導入分野】
今後、以下のような分野での活用が期待されています。
DGX Spark:
- 自動車メーカーでの自動運転AI開発
- 製薬企業での創薬AI研究
- クラウドサービス事業者のAI基盤構築
- 次世代自動運転車両への搭載
- スマートファクトリーでの検査ロボットへの組み込み
- ドローンやAMR(自律移動ロボット)への実装
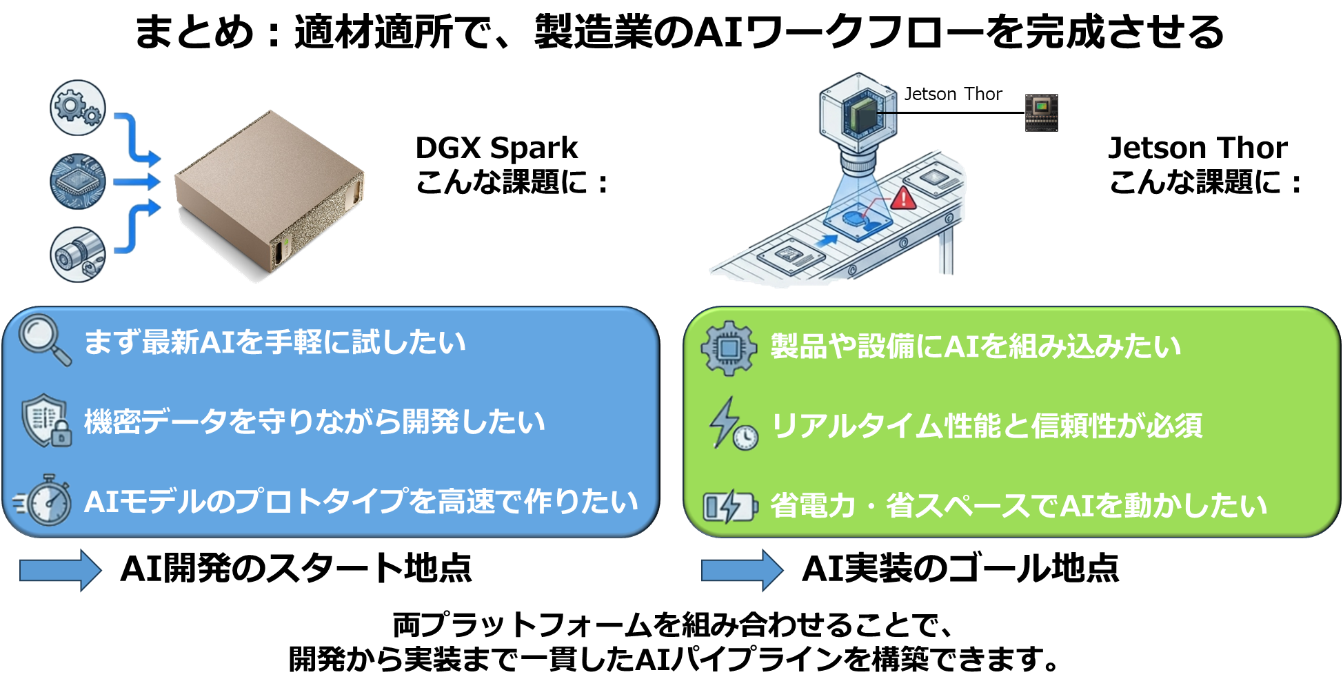
お客様のAIプロジェクトを成功させる鍵は、この「役割分担」を正しく設計することにあります。 「まずはDGX SparkでPoC(概念実証)を回し、完成したモデルをJetson Thorで現場展開する」。この勝ちパターンを採用することで、セキュリティ、コスト、そして開発スピードの課題を一挙に解決できるのです。
▼図16 DGX SparkとJetson Thorの適材適所
本記事をご参考に、貴社のAIプロジェクトにおいて「どこでAIを作り、どこでAIを動かすのか」を改めて設計してみるのはいかがでしょうか?
関連ページはこちら:
-[NVIDIA DGX Sparkとは?~超小型スパコンの誕生秘話~ スペックや強みもご紹介]
-[NVIDIA DGX Sparkとは?②~FP4×128GB統合メモリの実力~]
-[NVIDIA DGX Sparkとは?③ デスク上の“データセンター”を実現するネットワークとソフトウェア]
-[NVIDIA DGX Spark 製品ページ]
-[NVIDIA DGX Spark 専用のご購入・お問い合わせフォーム]
-[NVIDIA DGX Spark のよくある質問]
筆者プロフィール

小宮 敏博(こみや としひろ)
リョーサン菱洋株式会社|ソリューション事業本部 ソリューション技術部 営業技術G 経歴:KDDIで約8年システムエンジニアを経験後、ストレージベンダー・ソフトウェアベンダー・サーバーベンダーにてプリセールス、仮想化ソリューション、HCIビジネスの事業開発に従事。2022年から株式会社トゥモロー・ネットにてセールスエンジニアリング部門長およびソリューション/AIビジネス開発に従事。主にNVIDIA 商材を取り扱っていた。
2025年からは現職。リョーサン菱洋での実績は・・・NVIDIA AI EnterpriseとNVIDIA DGX Spark™をやっています! 専門分野:仮想化(VMware/Nutanix)関連、NVIDIA AI Enterprise/DGX Spark/LLM推論/AIインフラ(Cuda / Docker / Kubernetes / その他)など
現場目線で、GPU×生成AIの実務ノウハウをわかりやすく発信します。
#NVIDIA #nvidiaaienterprise #LLM推論 #dgxspark #GPU #aiblog
公開日:
最終更新日:




