

目次
- はじめに
- 1. GTC 2026 全体を貫くメッセージ
- 2. CUDA 20周年 - NVIDIAはチップ会社であると同時にアルゴリズム会社
- 3. DLSS 5 - グラフィックスにおける「GPTモーメント」
- 4. データ処理の加速 - 構造化データと非構造化データをどう扱うか
- 5. 推論のインフレクションポイント - AIは「会話」から「行動」へ
- 6. トークンエコノミクス - AIファクトリーはどう収益を生むのか
- 7. Vera Rubin - エージェントAI時代の新しい基盤
- 8. Groq 3 LPX 統合 - 低レイテンシ推論のための役割分担
- 9. OpenClaw / NemoClaw - エージェントAIを企業で安全に使うための仕組み
- 10. オープンモデル群 - NVIDIAはモデル戦略でも存在感を強めている
- 11. フィジカルAIとロボティクス - AIは画面の中から現実世界へ
- 12. AIファクトリーとDSX - 建てる前に、まずデジタルツインで試す
- 13. 産業別の広がり - NVIDIAは「どの業界で使われるか」まで語り始めた
- 14. ビジネス展望 - 1兆ドル規模の見通しが示すもの
- まとめ - GTC 2026は「GPU発表会」ではなく「AI産業の設計図」だった
- 用語ミニ解説
はじめに
2026年のNVIDIA GTC基調講演は、単に新しいGPUやサーバーを発表するイベントではありませんでした。NVIDIAの創業者/CEOであるJensen Huang (ジェンスン フアン)氏が示したのは、AIが「作るAI」から「考えて動くAI」へ進み、そのAIを社会実装するための基盤そのものが変わり始めている、という大きな潮流です。
今回の講演で何度も繰り返されたのは、AIの主戦場が学習から推論へ移ったということです。チャットするだけのAIではなく、資料を読み、道具を使い、判断し、現実世界にも働きかけるAIが本格化する。
そのために必要なのは、単体の半導体ではなく、データセンター、ネットワーク、ソフトウェア、モデル、運用まで含めた「AIファクトリー」だ、というのがNVIDIAのメッセージでした。
▼画像1. 基調講演の冒頭。Jensen Huang氏は、AI時代の次の中心テーマが「推論」であることを強調しながら全体像を提示した。

<この記事の要点>
• GTC 2026の主題は「学習中心のAI」から「推論中心のAI」への移行だった。
• NVIDIAはGPUメーカーではなく、AIファクトリー全体を設計・供給する企業としての姿を前面に出した。
• 推論の価値は「トークンをどれだけ効率よく生み出せるか」で測られ、データセンターの設計思想も変わりつつある。
• エージェントAIとフィジカルAIの拡大に向け、NVIDIA Vera Rubin、NVIDIA Dynamo、NVIDIA OpenShell、NVIDIA NemoClaw、NVIDIA DSX Airなどの基盤が並行して発表された。
1. GTC 2026 全体を貫くメッセージ
今年のGTCで最も重要だったのは、「AIの中心課題が学習から推論へ移った」という整理です。これまでのAIブームでは、大規模モデルをどう学習させるかが注目されてきました。ところが、実際に企業や社会で価値を生む局面では、学習済みのモデルをどう使い、どれだけ速く、安く、信頼性高く答えを返せるかが重要になります。Jensen氏は、AIが考えるにも、行動するにも、読むにも推論が必要だと述べました。これは、AIの価値がモデルの大きさだけではなく、実運用での応答速度、推論効率、長い文脈を扱う能力、そして外部ツールとの連携能力に移っていることを意味します。この見方に立つと、NVIDIAが売っているものはGPUだけではありません。トークンを安定して生み出し続ける工場、つまりAIファクトリー全体を設計することが競争力になる、というのが講演全体の土台でした。
2. CUDA 20周年 - NVIDIAはチップ会社であると同時にアルゴリズム会社
GTC 2026は CUDA®誕生20周年の節目でもありました。Jensen氏は、CUDAの価値を単なる開発ツールではなく、「開発者、アルゴリズム、市場、導入基盤が相互に回り続けるフライホイール」として説明しました。GPUが普及すると、開発者が集まり、新しい高速化手法やライブラリが生まれます。するとGPUでしか実現しにくい新しい市場が立ち上がり、さらに導入が広がる。この循環が20年かけて巨大化したことが、いまのNVIDIAの強さだというわけです。
▼画像2. CUDA 20周年の「フライホイール」概念。インストールベース、開発者、アルゴリズム、市場が循環しながら拡大していく構造を示している。

また、今回もCUDA-X™ Libraries群の拡充が強く打ち出されました。ここで重要なのは、NVIDIAがハードウェアを作るだけでなく、業種や用途ごとのアルゴリズム最適化まで自社で押さえていることです。Jensen氏がライブラリを「クラウンジュエル」と呼んだのは、その部分が価値の源泉だからです。
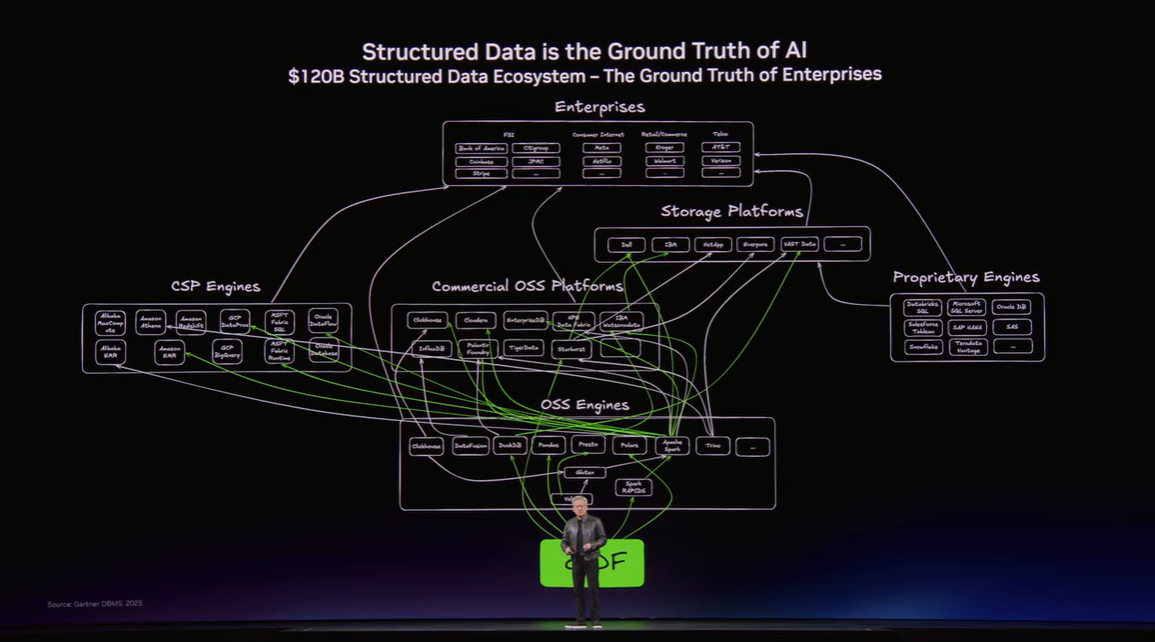
▼画像3. 構造化データと非構造化データ、さらに推論実行を結び付けるソフトウェア群の関係を示した図。NVIDIAがフルスタックで最適化を進めていることがわかる。
3. DLSS 5 - グラフィックスにおける「GPTモーメント」
一般の読者にとって、今回もっともイメージしやすい発表のひとつがNVIDIA DLSS 5でしょう。Jensen氏は、DLSS 5を「グラフィックスにおけるGPTモーメント」と表現しました。従来のDLSSは、主にアップスケーリングやフレーム生成によって見た目と性能を両立させる技術として知られていました。これに対してDLSS 5では、AIがピクセル単位の見え方に深く関与し、照明や質感表現そのものをニューラルレンダリングで高度化する方向が示されました。ポイントは、3Dグラフィックスのような「構造化された世界」と、生成AIのような「確率的な生成」を融合させていることです。制御しやすい構造化データを土台にすることで、AIを使っても破綻しにくい高品質な表現が可能になる、というNVIDIAらしい考え方がここにも表れています。
▼画像4. DLSS 5のデモ画面。リアルタイムのゲーム描画に対して、AIが光や質感の表現を強化し、フォトリアルな見え方へ近づける方向性を示している。

4. データ処理の加速 - 構造化データと非構造化データをどう扱うか
企業がAIを本格導入するうえで避けて通れないのが、データ処理の問題です。SQLやPandasで扱う表形式データだけでなく、PDF、画像、音声、動画といった非構造化データをどう理解し、検索し、推論に生かすかが差別化の鍵になります。Jensen氏は、世界のデータの大部分は非構造化であり、これまでは十分に活用できていなかったと説明しました。マルチモーダルAIの進化によって、そのデータが初めて本格的に使えるようになってきた、という整理です。
主要パートナーとの連携
講演では、主要クラウドやエンタープライズ企業との提携も紹介されました。
IBM、Google Cloud、AWS、Microsoft Azure、Oracle Cloud、CoreWeave、Palantir、Dellなどとの連携は、NVIDIAの技術が「研究用途」ではなく「実務の現場」へ広がっていることを示しています。
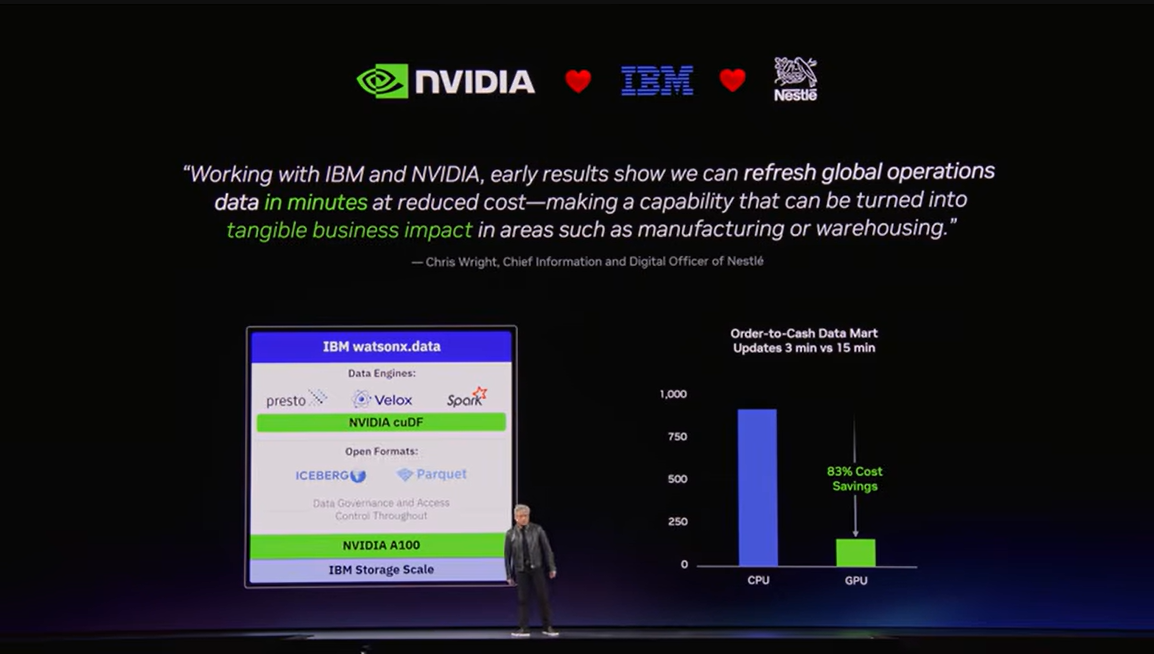
▼画像5. IBM との協業例。watsonx.data の SQL エンジンを GPU で加速し、実運用で速度向上とコスト削減を両立する方向を示している。
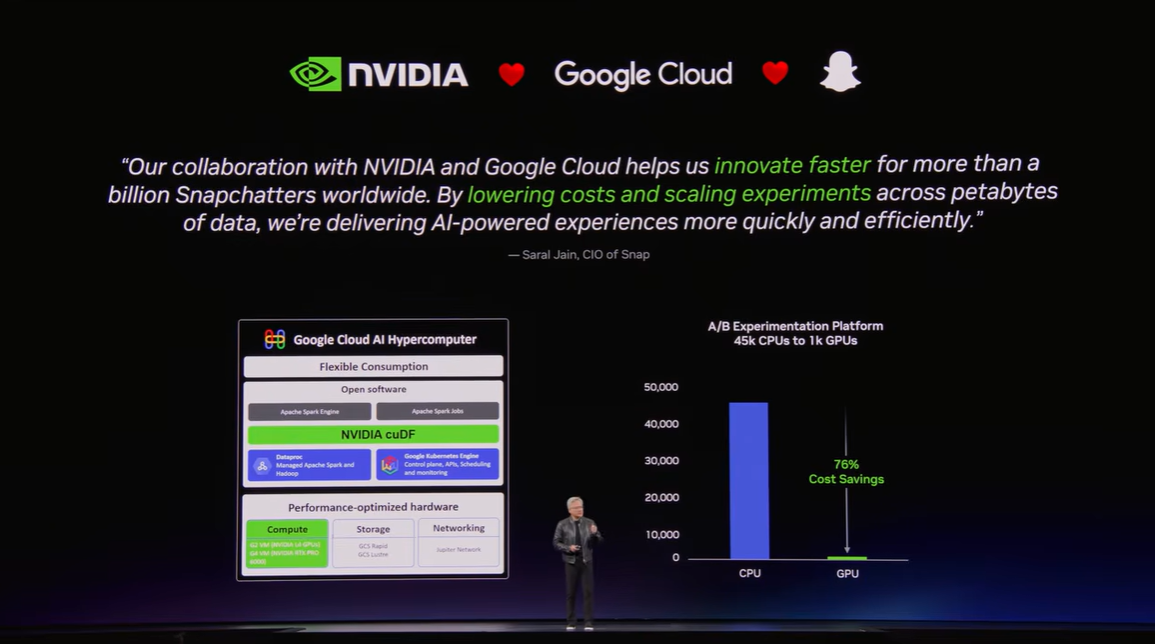
▼画像 6. Google Cloud との協業例。BigQuery や Vertex AI などのクラウド基盤上で、GPU 加速を活用して分析・推論コストを下げる考え方を示したスライド。
5. 推論のインフレクションポイント - AIは「会話」から「行動」へ
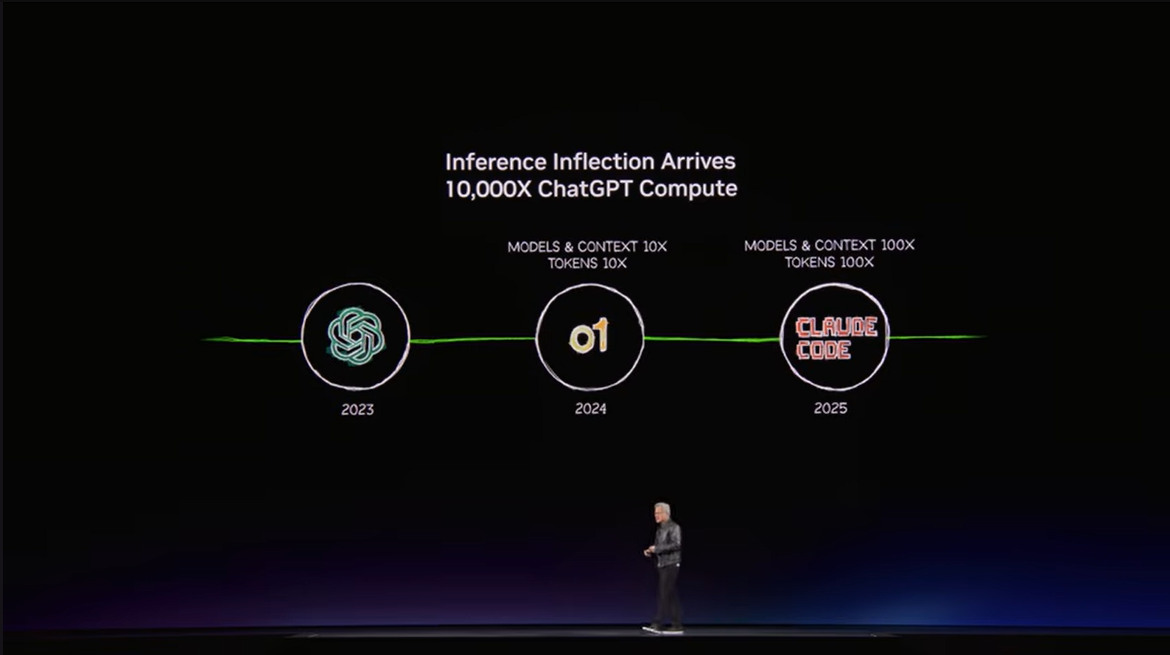
今回の講演の中核は、推論需要が一気に立ち上がったという認識です。生成AIの登場で「AIが文章を作る」ことが広く知られ、そこから「AIが考える」「AIが行動する」段階へ進んだ結果、1回のタスクに必要な計算量は急増しています。ブログとしてわかりやすく言い換えるなら、AIは「質問に答えるだけの存在」から、「手順を考え、必要な情報を集め、道具を使って仕事を進める存在」へ変わりつつあります。NVIDIAがここで強調したのが、Claude CodeやCodex、Cursorのようなエージェント型ツールの実用化です。
▼画像7. 生成 AI、推論 AI、エージェントAI へと重心が移っていく流れを示したスライド。GTC 2026 の主題が「推論の時代」であることを視覚的に表している。
6. トークンエコノミクス - AIファクトリーはどう収益を生むのか
Jensen氏が「講演で最も重要なチャート」と呼んだのが、AIファクトリーの収益モデルです。ここでの考え方は非常にシンプルで、データセンターはもはや単なるファイル置き場ではなく、電力を使ってトークンを生み出し、そのトークンが売上になる工場(ファクトリー)だというものです。この見方に立つと、重要なのは単純な演算性能ではありません。トークンをどれだけ低コストで、どれだけ素早く、どれだけ高い品質で生み出せるかが経営指標になります。無料枠のような高スループット用途から、長文脈・高精度推論のプレミアム用途まで、サービス階層ごとに最適なインフラ設計が求められるのです。
| ティア | 内容と価格帯のイメージ |
| フリー | 小規模モデルを高効率で回す層。おおむね3ドル/100万トークン級。 |
| ミディアム | より大きなモデルを高速応答で提供する層。おおむね6ドル/100万トークン級。 |
| ハイ | 長い文脈や高性能モデルを使う層。おおむね45ドル/100万トークン級。 |
| プレミアム | 深い推論や研究用途向けの超高付加価値層。おおむね150ドル/100万トークン級。 |
▼画像8. AIファクトリーを「AI 時代の産業インフラ」と位置付けたスライド。電力をトークンへ変換し、収益へつなげる考え方を示している。

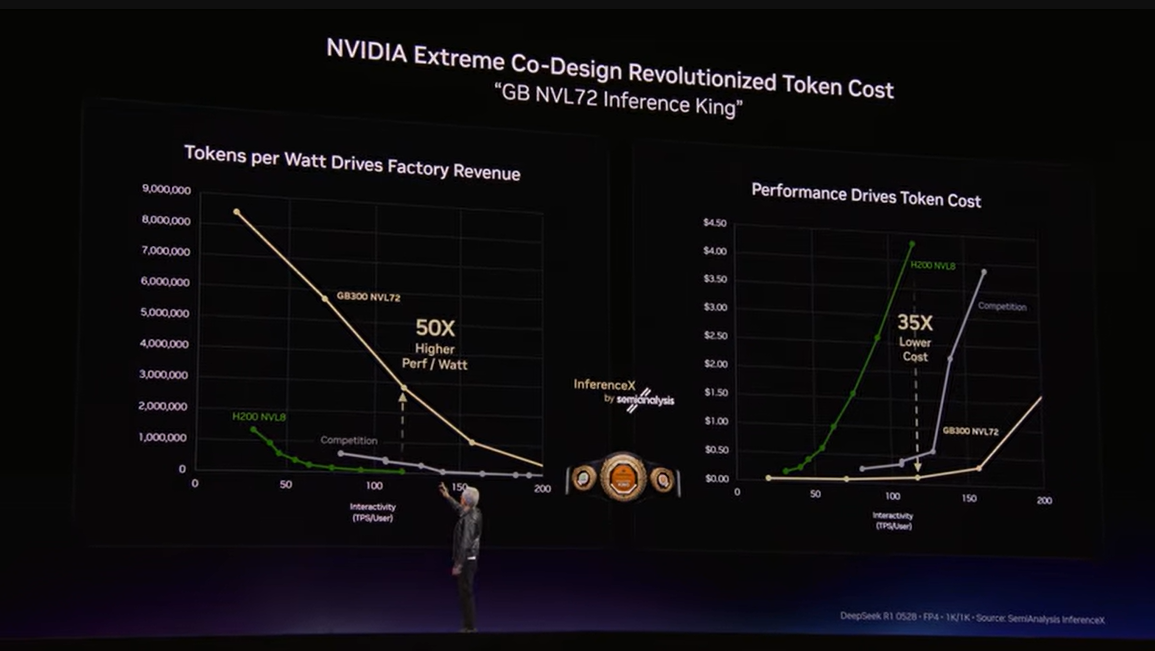
▼画像 9. NVIDIAの共同設計によってトークンコストを大きく下げられる、という主張を示すスライド。単体のチップ性能ではなく、システム全体の最適化が鍵であることを表している。
7. Vera Rubin - エージェントAI時代の新しい基盤
Vera Rubinは、単なる次世代GPUの名前ではありません。NVIDIAはこれを、エージェントAI時代に最適化された新しいプラットフォームとして打ち出しました。GPUだけでなく、CPU、ストレージ、ネットワーク、推論アクセラレータまで含めたラックスケール設計が特徴です。注目すべきは、AIファクトリーを構成する部品を個別最適化するのではなく、「推論のどの段階で何がボトルネックになるか」を前提に全体設計している点です。つまり、前処理、推論、デコード、KVキャッシュ、ネットワーク転送、冷却までを一体として見ているわけです。
▼画像10. Vera Rubinプラットフォームの全体像。複数のラック種別を組み合わせて、AIファクトリー全体を構成する考え方を示している。

NVIDIA Vera CPUが重要視された理由
今回の講演では、GPUだけでなくCPUの位置付けも大きく扱われました。エージェントAIや強化学習では、大量のツール実行や環境シミュレーションが必要になります。そのため、GPUの周辺で動くCPU環境も高速でなければ、全体の効率が頭打ちになります。
▼画像11. Vera CPU ラックの説明場面。エージェントAI や強化学習では、GPU だけでなく大量の CPU 実行環境が重要になることを示している。

8. Groq 3 LPX統合 - 低レイテンシ推論のための役割分担
講演では、NVIDIA Groq 3 LPXラックもVera Rubinプラットフォームの一部として紹介されました。ここでの考え方は明快で、高スループットと低レイテンシはしばしば両立しにくいため、推論工程の役割に応じて最適なプロセッサを組み合わせる、というものです。入力をまとめて処理するプリフィルはGPUが得意で、トークンを順番に吐き出すデコードは極端なメモリ帯域や決定論的な動作が重要になります。そこでLPUを組み合わせることで、応答遅延を抑えつつ、電力当たりの推論効率を高める構想が示されました。
▼画像 12. Groq 3 LPX ラックの説明スライド。大規模文脈かつ低レイテンシな推論ニーズに向けた専用ラックとして位置付けられている。

▼画像 13. 推論処理を段階ごとに分け、GPUとLPUの得意分野を組み合わせる考え方を示した図。NVIDIAが「協調型の推論基盤」を目指していることがわかる。
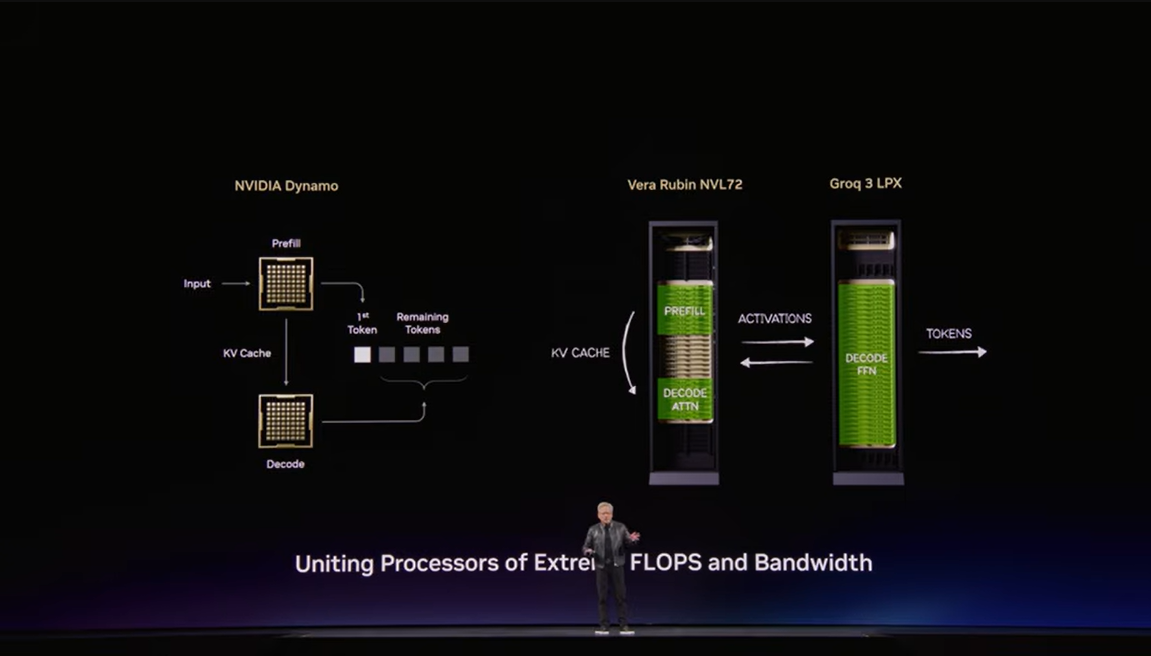
▼画像 14. チップからラックまでを共同設計し、AIファクトリー全体として効率を高めるという NVIDIAの思想を示したスライド。

9. OpenClaw/NemoClaw - エージェントAIを企業で安全に使うための仕組み
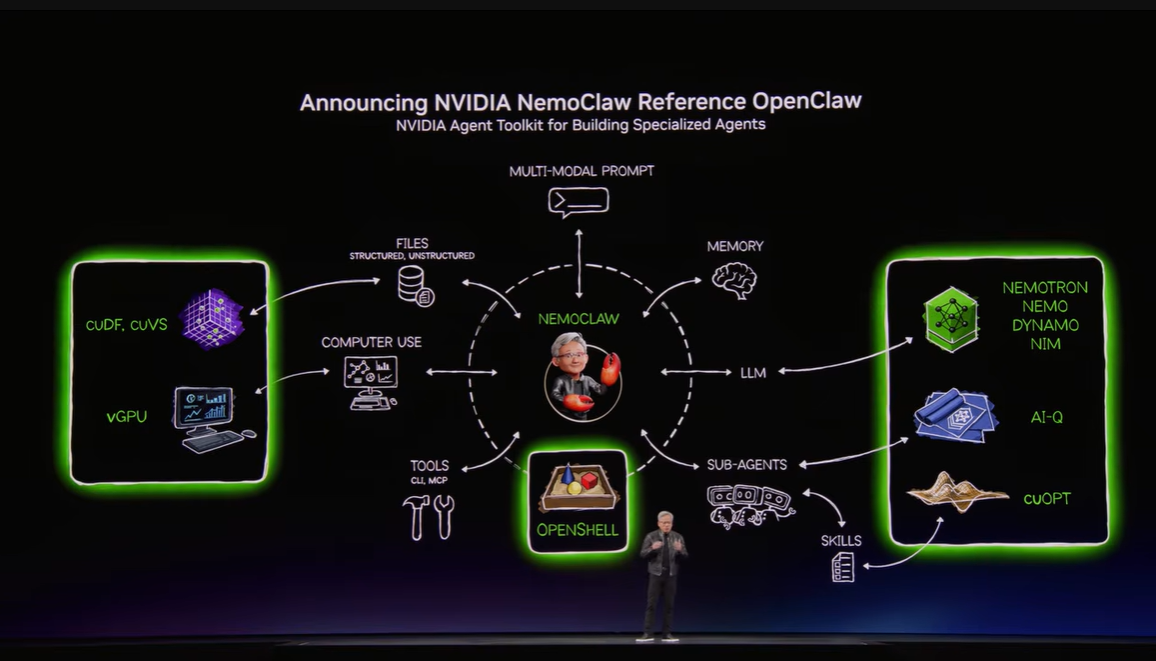
エージェントAIが普及するほど、企業は「AIにどこまで権限を渡してよいのか」という問題に直面します。社内文書へアクセスし、コードを実行し、外部サービスと通信できるAIは便利ですが、同時に利用・運用リスクも大きくなります。そこでNVIDIAが提示したのが、OpenClawコミュニティとOpenShellを中心にしたオープンな実行基盤と、それを企業向けに安全にまとめるNemoClawです。ポイントは、エージェントに必要な権限を与えつつ、ポリシー、ネットワーク、プライバシーのガードレールを同時に敷くことです。
▼画像 15. エージェントAI のコンピューティング基盤を整理した図。モデル、ツール、メモリ、実行環境、ガードレールを一体で考える必要があることを示している。
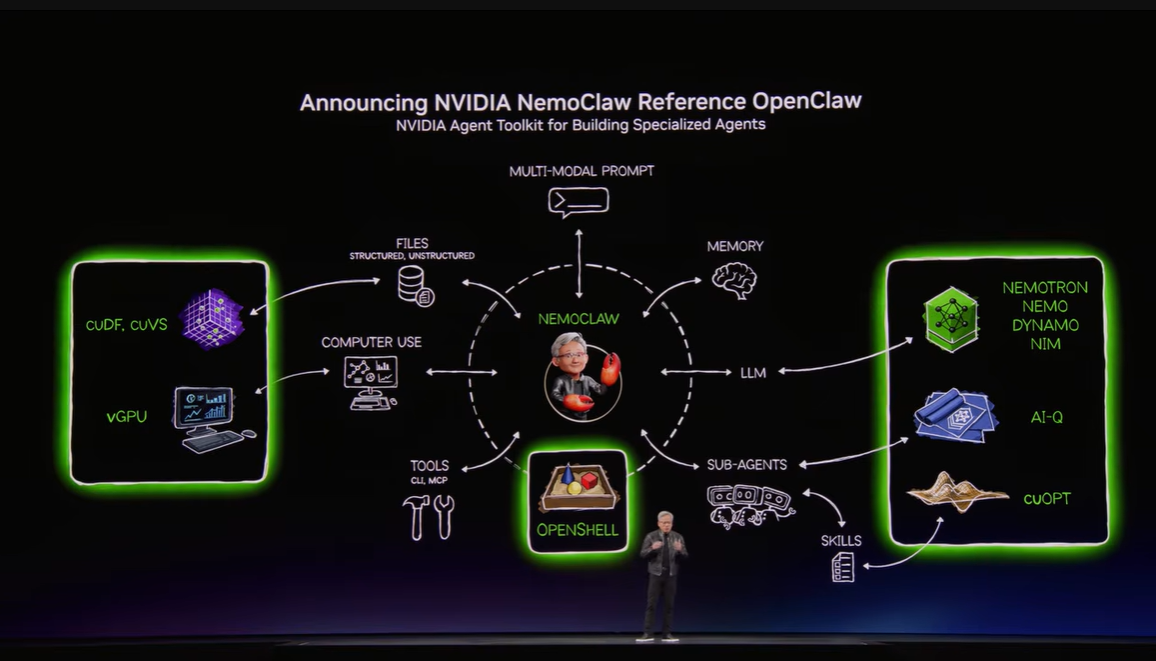
▼画像 16. OpenClawと NemoClawの関係を示したスライド。自律エージェントを実務で安全に使うための実行基盤が必要であることを説明している。
10. オープンモデル群 - NVIDIA はモデル戦略でも存在感を強めている
今回の講演では、NVIDIAがインフラだけでなく、オープンモデル群でも存在感を強めていることが明確になりました。言語・視覚・検索拡張・安全性・音声・ロボティクス・自動運転・創薬など、用途別にモデルファミリーを拡充しています。ここで重要なのは、NVIDIAが「自社で全部を囲い込む」方向ではなく、オープンなモデルとツールを増やし、それを自社インフラやソフトウェアと噛み合わせる戦略を取っている点です。つまり、GPUを売るためのモデルではなく、モデルを含めたエコシステム全体を強くする戦略です。
▼画像 17. NVIDIA の主要なオープンモデル群を並べたスライド。言語、物理 AI、医療・生命科学など、多分野へ広げていることがわかる。
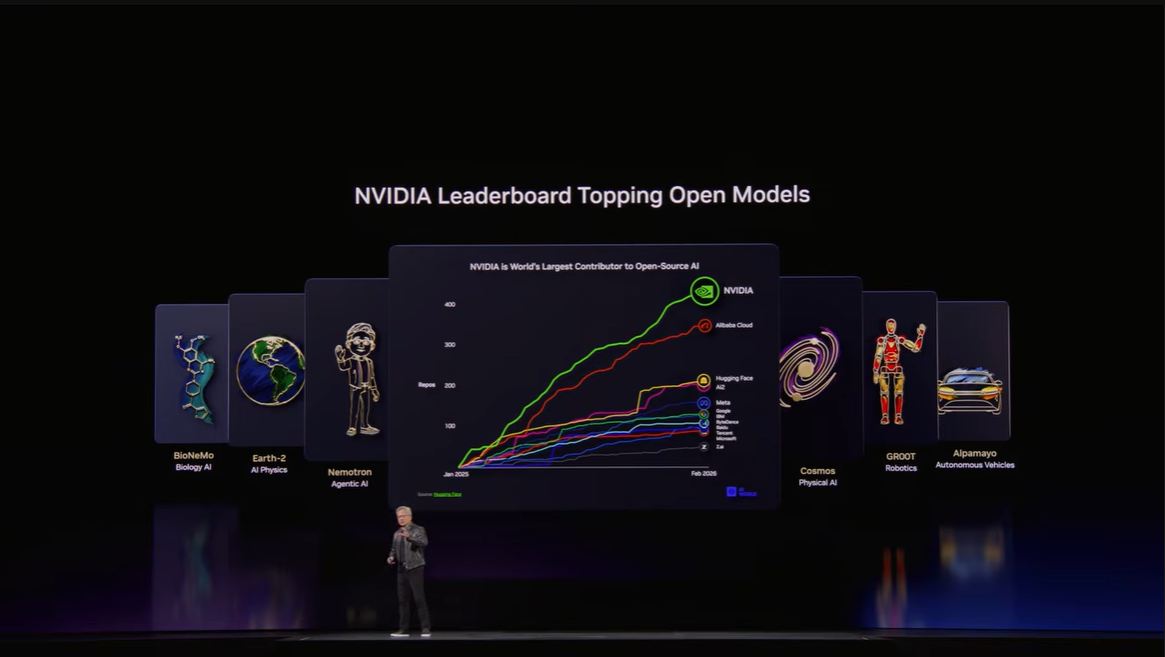
▼画像 18. オープンモデルを採用するパートナーやユースケースを示した一覧。モデルそのものより、実運用へどう組み込まれるかが重視されている。
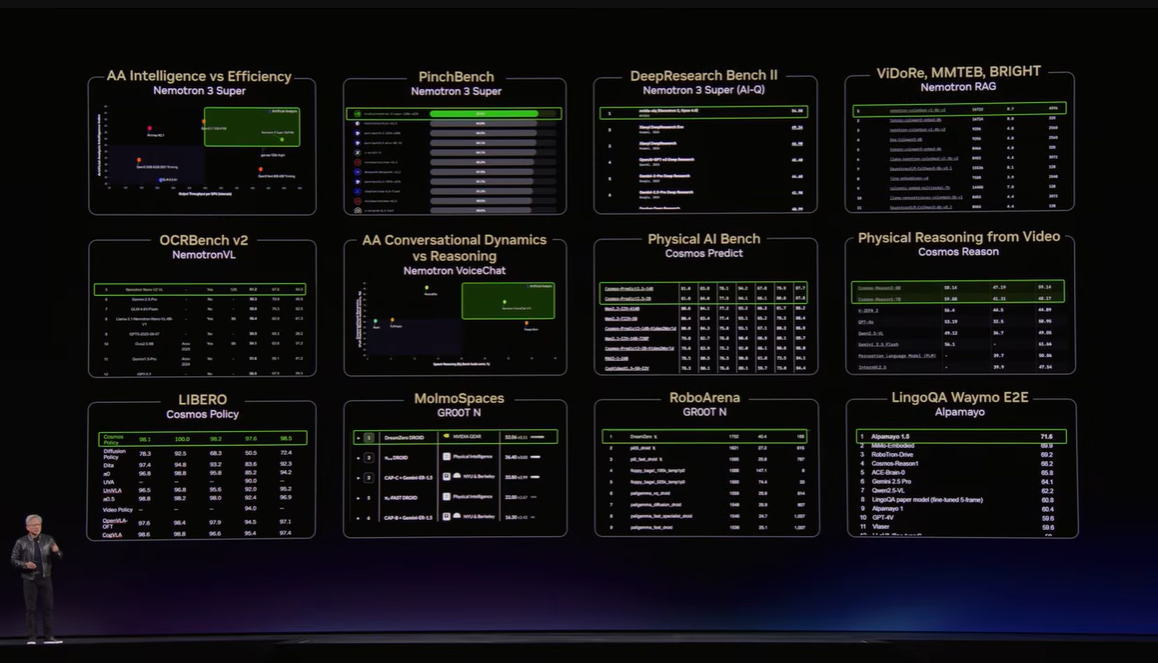
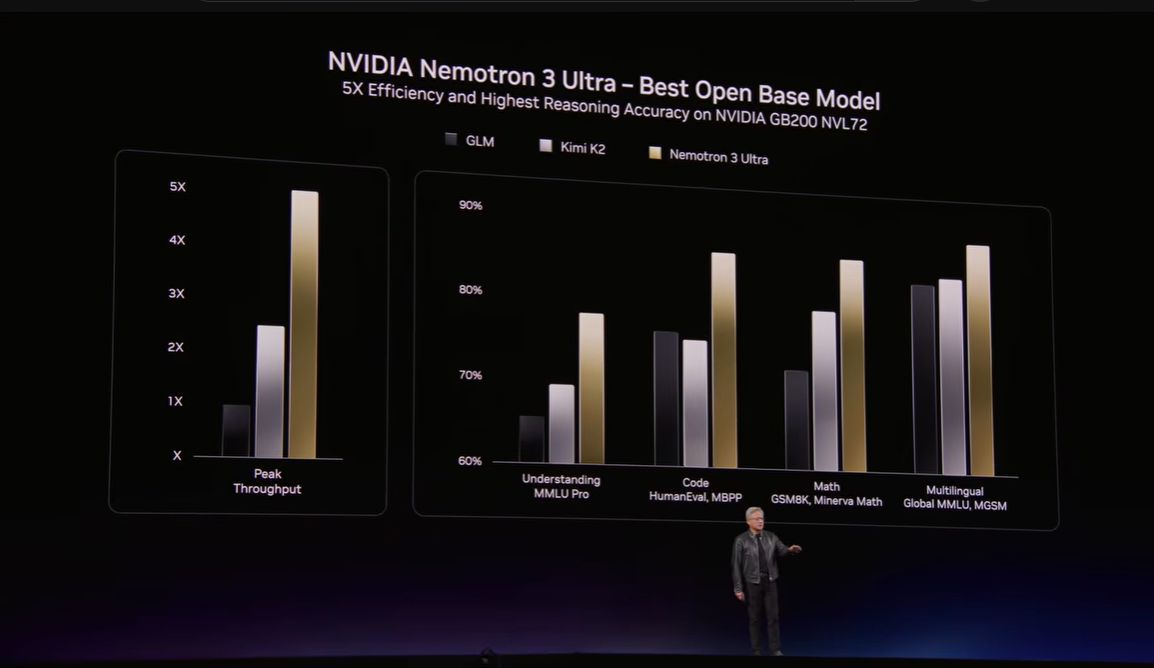
▼画像 19. NVIDIA Nemotron 3 Ultraの性能訴求スライド。オープンモデルでも高い推論性能を狙うNVIDIAの姿勢を示している。
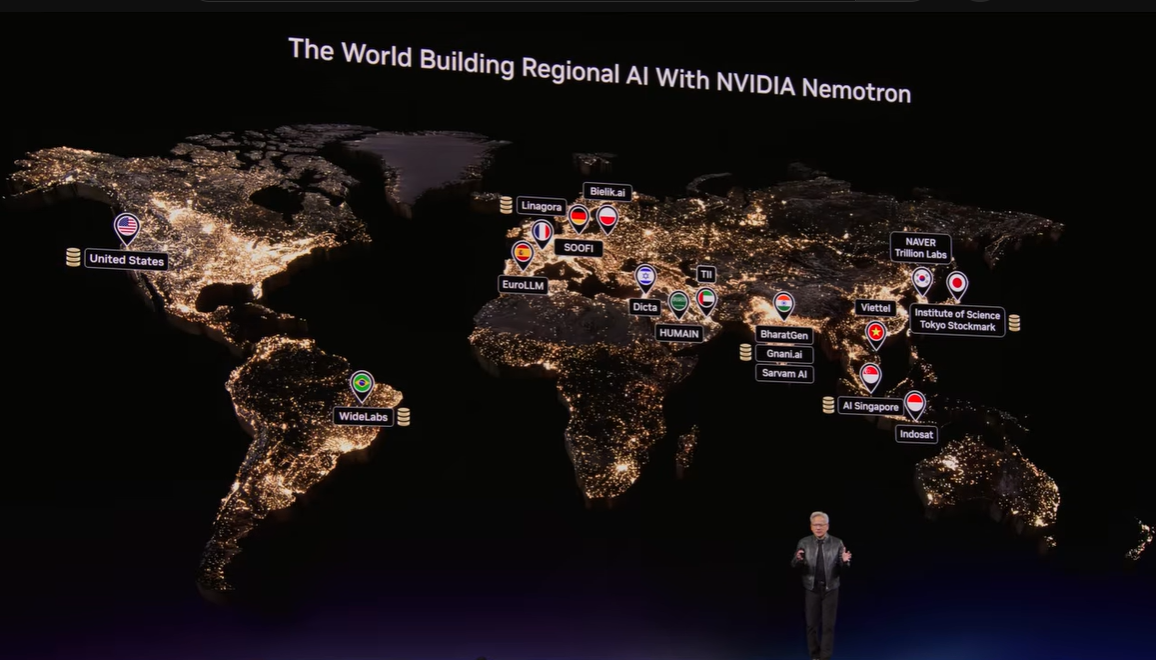
▼画像 20. 各地域・各国へ広がるNVIDIA Nemotronの展開イメージ。ソブリン AIや地域ごとのAI基盤整備とも結び付けて説明されている。
11. フィジカルAIとロボティクス - AIは画面の中から現実世界へ
GTC 2026では、AIがソフトウェアの中だけで完結しないことも強く印象付けられました。自律走行、産業ロボット、ヒューマノイド、物流、通信インフラなど、物理世界で動くAIが一段と前に出てきています。ここでNVIDIAが重視しているのは、現実世界でいきなり学習するのではなく、まず仮想空間やシミュレーションで大量に試し、そこから実機へ移す流れです。これがNVIDIA Isaac™、Newton、NVIDIA Cosmos™、NVIDIA Isaac™ GR00T、Physical AI Data Factory Blueprint へつながります。
▼画像 21. ヒューマノイド系のデモ画面。ロボットが視覚・言語・行動を組み合わせ、現実環境で判断する方向性を表している。

▼画像 22. ロボット制御や物理シミュレーションの例。AI モデルとシミュレーション環境を結び付けて訓練する流れを示している。
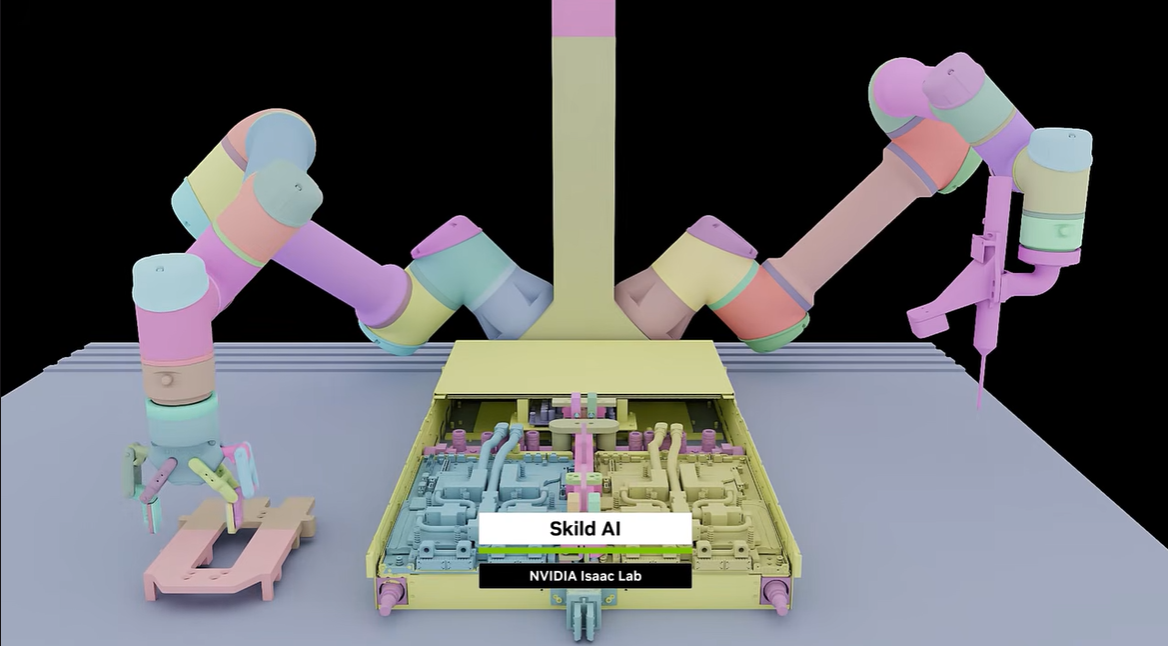
▼画像 23. 工場や物流現場を想定したロボティクスシミュレーション。実環境の前に仮想空間で大量の試行を行うフィジカル AIの考え方に対応している。

▼画像 24. Disney Researchのオラフロボットがステージ上でJensen氏と対話する場面。フィジカル AIが一般の観客にも伝わる象徴的なデモだった。

12. AIファクトリーとDSX - 建てる前に、まずデジタルツインで試す
AIファクトリーは、単にGPUを並べれば完成するものではありません。ラック配置、電力、冷却、ネットワーク、ストレージ、運用まで含めて、巨大なシステムとして成立させる必要があります。そこでNVIDIAが押し出したのがDSXです。簡単に言えば、「実際に巨大なAIデータセンターを建てる前に、まずデジタルの双子を作って、設計・建設・運用を先に検証する」ための基盤です。AIファクトリーを製造業の工場のように設計・最適化する発想がここにあります。画像 26. DSX AI Factory Platform の概要図。計算機、ネットワーク、ストレージ、施設設計までを統合的に扱う基盤であることを示している。
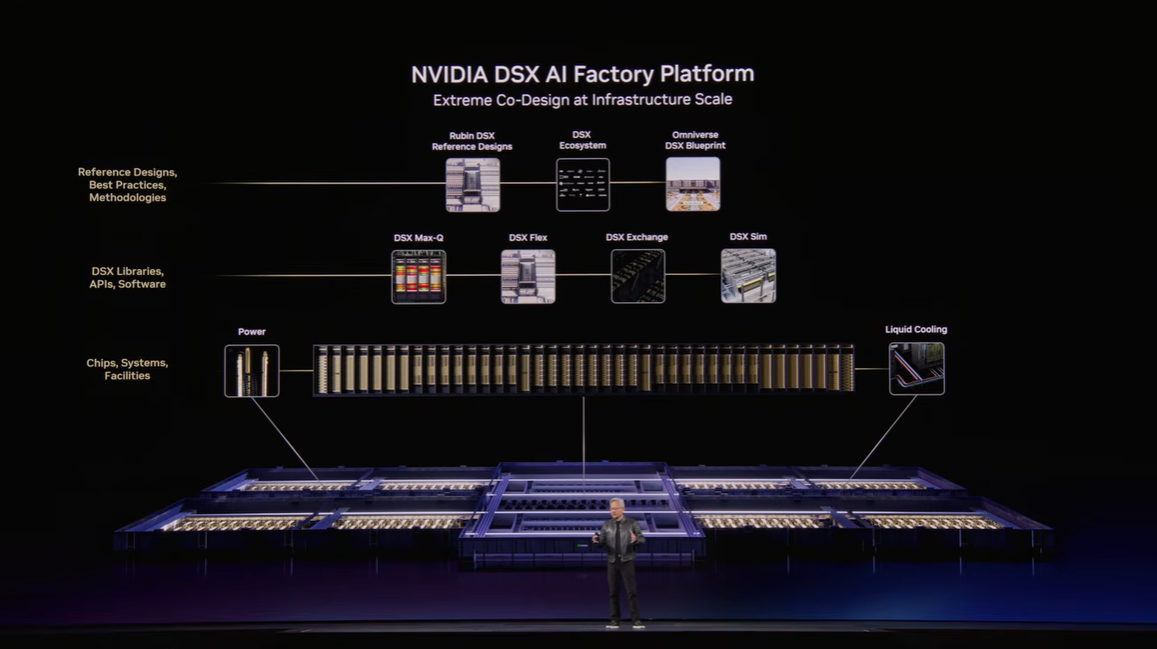
▼画像 25. DSX のエコシステムと機能群を示したスライド。設計、シミュレーション、運用データ連携、電力最適化まで広く含まれる。

▼画像 26. Space-1 Vera Rubin Module のスライド。NVIDIA が AIファクトリーの考え方を宇宙空間へまで拡張しようとしていることを示している。

13. 産業別の広がり - NVIDIAは「どの業界で使われるか」まで語り始めた
今回の基調講演は、技術のすごさを語るだけでなく、それがどの産業で使われるのかをかなり具体的に示していた点も印象的でした。金融、ヘルスケア、通信、製造、設計・CAE、量子計算、小売まで、ほぼあらゆる業界が対象になっています。これは、AIが特定のIT企業だけの武器ではなく、各業界の業務システムや現場設備へ組み込まれる段階に入ったことを意味します。NVIDIAが「AI産業全体の基盤会社」へ位置付けを変えようとしている理由もここにあります。
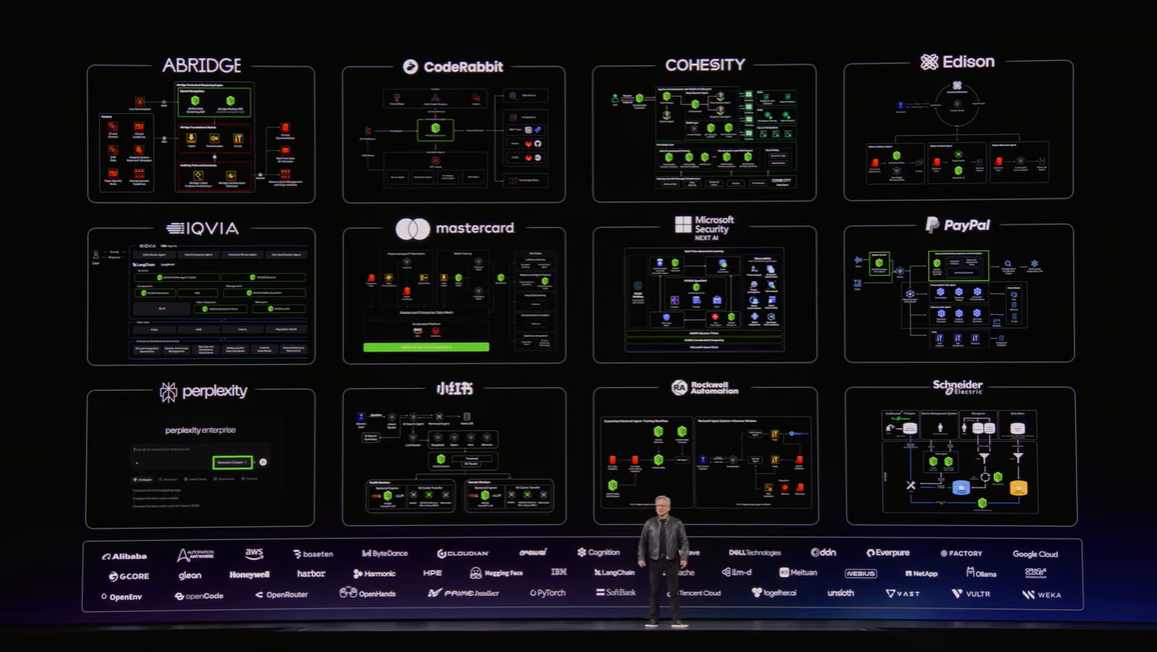
▼画像 27. 産業別・パートナー別の広がりを一覧化したスライド。AI が単一分野ではなく、複数産業へ同時に浸透していることが読み取れる。
14. ビジネス展望 - 1兆ドル規模の見通しが示すもの
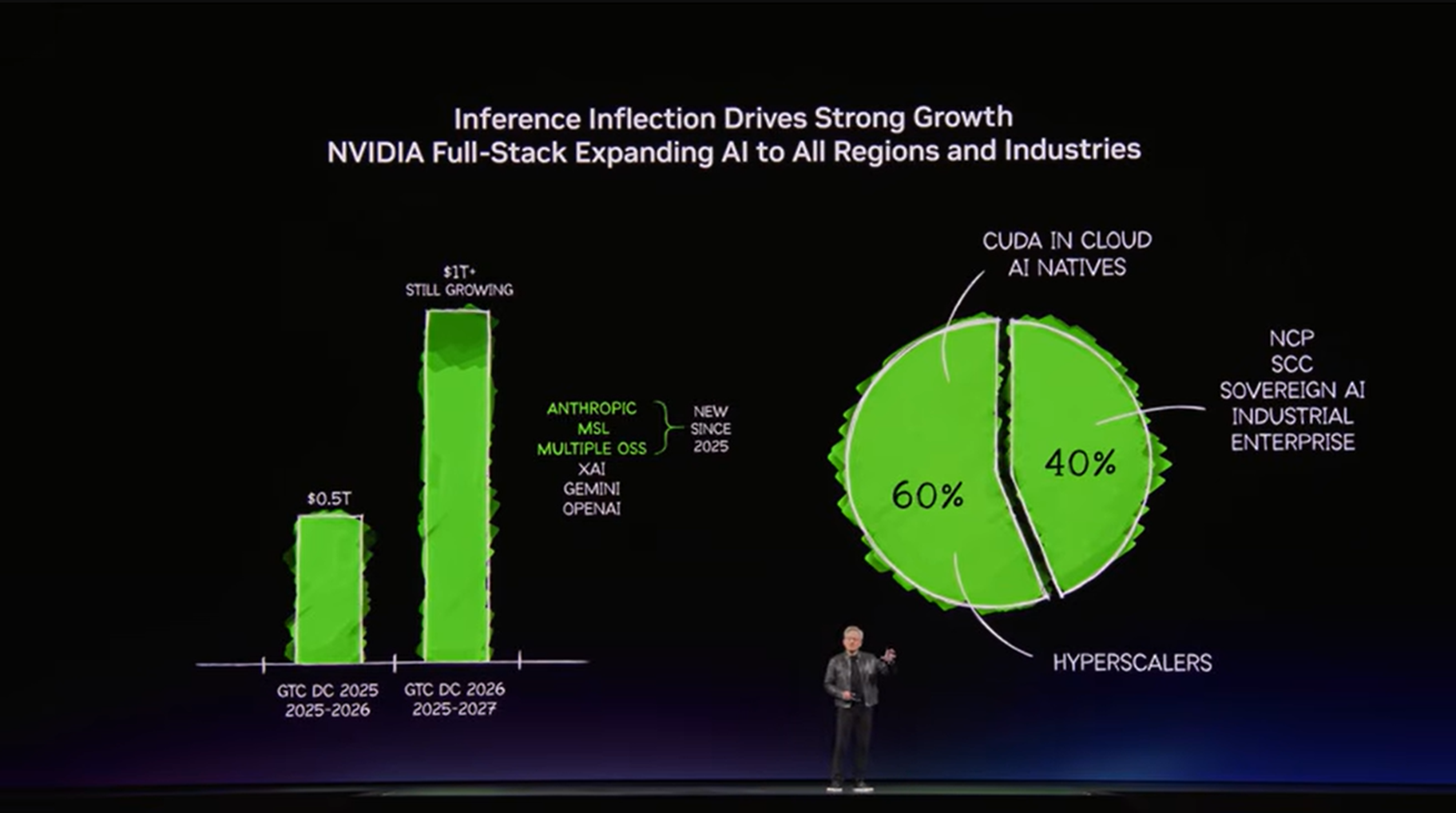
講演後半では、NVIDIA BlackwellおよびVera Rubinを軸にした大きな受注見通しも示されました。ここで注目すべきなのは、ハイパースケーラーだけでなく、リージョナルクラウド、ソブリンクラウド、エンタープライズ、ロボティクス、エッジへ需要が広がっていると説明された点です。言い換えると、AIインフラ投資は一部の巨大企業だけのものではなくなりつつあります。企業や自治体、産業分野ごとに「自分たちのAI基盤」を持つ流れが強まり、その結果として、AIファクトリー市場がさらに広がるとNVIDIAは見ています。
▼画像 28. 受注見通しと市場構成を示すスライド。ハイパースケーラーだけでなく、多様な地域・産業へ AI インフラ需要が広がるという見立てを表している。
まとめ - GTC 2026 は「GPU発表会」ではなく「AI産業の設計図」だった
今回のGTC 2026基調講演をひと言でまとめるなら、NVIDIAが「GPU企業」から「AI産業全体の設計者」へと自らを位置付け直した場だったと言えます。推論を中心に据え、トークンを収益の単位として捉え、AIファクトリーを新しい産業インフラと見なす。
そのうえで、エージェントAI、フィジカルAI、デジタルツイン、オープンモデル、推論OS、ラックスケール設計までを一本の物語としてつないだのが、今年の基調講演でした。
一般の人にとって重要なのは、「AIがさらに賢くなった」という点だけではありません。AIが働く仕組み、企業がAIを使うコスト構造、そして現実世界へAIを実装するための基盤そのものが変わり始めていることです。GTC 2026は、その変化をかなりはっきり見せたイベントでした。
用語ミニ解説
| 用語 | 意味 |
| Token | AIが読み書きする最小単位。AIファクトリーでは「生産量」や「売上」の尺度にもなる。 |
| Inference | 学習済みモデルを実際に使って答えを出す処理。企業活用ではここが主戦場になる。 |
| AI Factory | 大量の推論を回し、トークンを安定供給するための次世代データセンター。 |
| Agentic AI | 指示を受けて終わるのではなく、手順を考え、道具を使いながら作業を進めるAI。 |
| Physical AI | ロボットや自動運転など、現実世界で動くAI。 |
| Digital Twin | 現実の設備やシステムを仮想空間に再現し、事前に検証する手法。 |
| Dynamo | AIファクトリー向けの推論基盤ソフトウェア。推論処理を効率よくさばく役割を担う。 |
| OpenShell / NemoClaw | エージェントAIを安全に動かすためのオープン実行基盤と企業向け導入スタック。 |
※注記
本稿は、添付の元原稿に含まれる内容をベースに、NVIDIA GTC 2026 Keynoteの公開向けブログ記事として読みやすく再構成したものです。画像説明は、本文との対応がずれないよう、各スライドが何を示しているかを短く補足する形で追記しています。
技術仕様や提携情報のうち、講演での表現とニュースリリースでの表現に差がある箇所は、公開記事として誤解が広がりにくいように表現をやや抑えて整理しています。
筆者プロフィール

小宮 敏博(こみや としひろ)
菱洋エレクトロ株式会社|ソリューション事業本部 ソリューション技術部 営業技術G
経歴:KDDIで約8年システムエンジニアを経験後、ストレージベンダー・ソフトウェアベンダー・サーバーベンダーにてプリセールス、仮想化ソリューション、HCIビジネスの事業開発に従事。
2022年から株式会社トゥモロー・ネットにてセールスエンジニアリング部門長およびソリューション/AIビジネス開発に従事。主にNVIDIA 商材を取り扱っていた。
2025年からは現職。菱洋での実績は・・・NVIDIA AI EnterpriseとNVIDIA DGX Spark™をやっています!
専門分野:仮想化(VMware / Nutanix)関連、NVIDIA AI Enterprise / DGX Spark / LLM推論 / AIインフラ(Cuda / Docker / Kubernetes / その他)など
現場目線で、GPU×生成AIの実務ノウハウをわかりやすく発信します。
#NVIDIA #nvidiaaienterprise #LLM推論 #dgxspark #GPU #aiblog
最終更新日:

