

目次
高性能なAI開発は、長らく大規模データセンターや高価なクラウドインスタンスを使える組織に限られてきました。巨大化し続けるAIモデルを扱うには、膨大なメモリと計算能力が不可欠であり、多くの開発者や研究者はリソース不足や高額なコスト、そして機密データのセキュリティリスクのような制約に常に直面してきました。
しかし今、この状況を根本から変える新しいデバイスが私たちのデスク上に登場しました。
それが、NVIDIA DGX Spark™です。
DGX Sparkは、AIの構築と実行のためにゼロから設計された新しいクラスのコンピューターであり、その登場は「パーソナルAIスーパーコンピューター」の時代の幕開けを告げています。
今回はDGX Sparkについての紹介や誕生秘話なども含めてご説明します。

~デスクトップAIコンピューティングの必要性~
生成AIモデルの規模と複雑さの増大により、ローカルシステムでの開発作業は困難を極めています。大規模モデルをローカルで扱うには、大量のメモリが必要です。
さらにプロトタイピングや推論には、高度なコンピューティング性能も求められます。企業、ソフトウェアプロバイダー、政府機関、スタートアップ企業、そして研究者がAI開発に注力するにつれ、AIコンピューティングリソースの必要性は高まり続けています。
デスク上の200B(2,000億) パラメータモデルDGX Sparkは、AIの構築と実行のためにゼロから設計された新しいクラスのコンピューターです。NVIDIA GB10 Grace Blackwellスーパーチップを搭載し、NVIDIA Grace Blackwellアーキテクチャをベースとし、最大1ペタフロップス(petaFLOPS)のAIパフォーマンスを実現し、大規模なAIワークロードに対応します。128GBの統合システムメモリにより、開発者は最大2,000億個のパラメータを持つモデルの実験、ファインチューニング、推論を行うことができます。 さらに、NVIDIA Connect-X™ネットワークにより、2台のDGX Sparkスーパーコンピューターを接続することで、 最大4050億個のパラメータを持つモデルでの推論が可能になります。
DGX Sparkの誕生は、AIモデルの巨大化とともに歩んできたDGXシリーズの系譜の延長にあります。
2016年、OpenAIがGPTシリーズの前身モデルの開発に用いた初代DGX-1は、当時のAI研究を支える象徴的なスーパーコンピューターでした。
AIモデルの規模は数年ごとに100倍のペースで拡大し、必要なコンピュートリソースも指数関数的に増加してきました。
▼図2 AI大規模化のマイルストーン
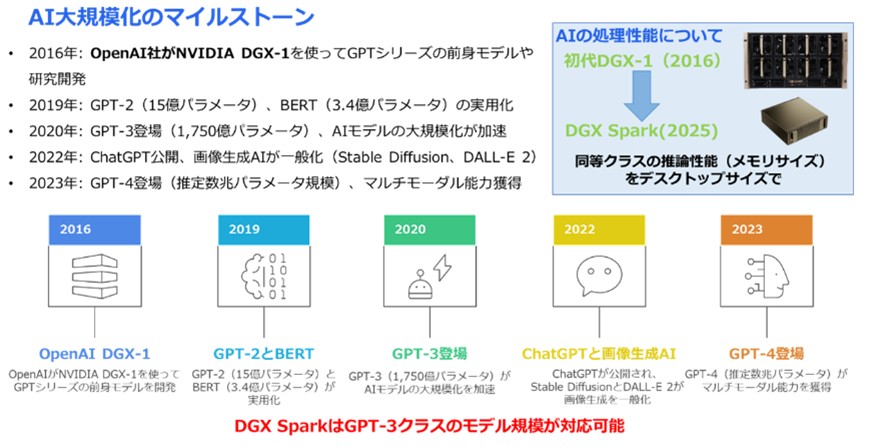
AIモデル巨大化の象徴であるDGX-1と、その性能をデスクトップサイズで実現したDGX Sparkは、対照的な存在です。
以下に両者の主要な仕様を比較します。
▼表1 仕様比較:NVIDIA DGX-1 vs NVIDIA DGX Spark
*スパース化機能適用時のFP4における理論上のPFLOP値
図2で示しているように、モデルの規模は数年ごとに100倍のベースで増えてきており、これに伴い、必要なコンピュートリソース(GPU数、メモリ要件、電力消費)も指数関数的に増大し、学習コストは急増しています。
そこで今後の競争力のカギは、ローカルで高性能なコンピュートを確保することが求められています。
そのため、多くの企業では数千万円〜数億円規模の投資が必要となっていました。加えて電力設備や保守費用などのコスト負担も強いられることになってしまいました。
それだけではなく、インフラチームのスキル・人手不足で運用も難しくなっています。
解決策:
DGX Sparkは、スモールスタートが可能なハードウェアであり、専用GPUリソースを即座に利用可能にして、プロトタイプやスモールスタートを可能にします。複雑な設定なしで、すぐに開発・検証が開始できます。
例えば、PoCで利用する分にはコストは安いですが、本番利用ではコストが跳ね上がってしまいます。また、オンプレミス環境ではないため、大容量データの転送がボトルネックになってしまうことがあり、また、クラウド環境においては、自社固有の要件に合わせづらく、無理やり合わせようとするとコストがかかってしまい、カスタマイズに制限を受けます。
解決策:
DGX Sparkを導入して、ローカル処理により低遅延を実現し、クラウド依存を減らして予算を安定化させ、長期的なTCO(総所有コスト)の削減に貢献します。オンプレミスに近い自由度でワークロードを最適化可能です。
データ主権の観点から、機密データを海外クラウドに預けづらいと考える企業も多く、クラウド利用における情報漏洩リスクを懸念する声もあります。
また日本企業では、業界ごとの法規制により、厳しい運用要件が求められるケースもあります。
解決策:
DGX Sparkは、オンプレミス完結にデータ処理を可能にし、機密データを外部に出さずに安全に利用できます。特に金融、医療、製造などの規制産業での活用に最適です。
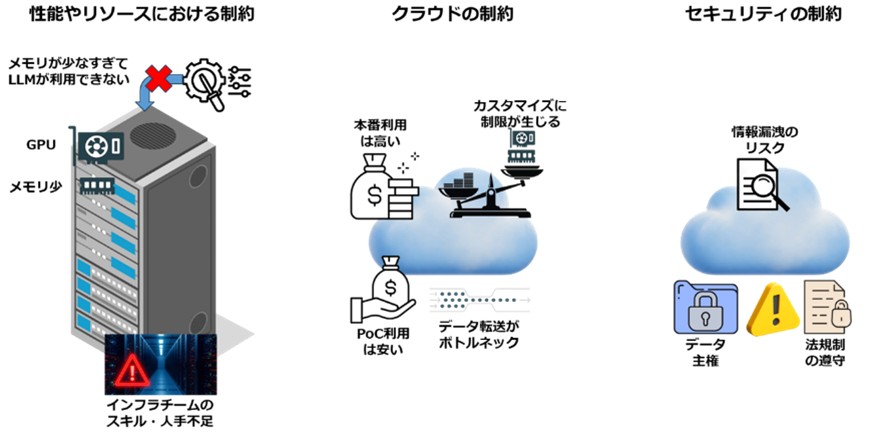
▼図3 開発現場の3つの制約
▼表2 DGX Spark 詳細スペック
*スパース化機能適用時のFP4における理論上のPFLOP値
▼図4 DGX Spark ハードウェア仕様

・GPU:Blackwell GPU(第5世代 Tensor コア搭載)
・Tensor Performance: FP4精度(スパース性特性を用いた理論値)で最大1petaFLOPS(1,000 AI TOPS)の性能を実現
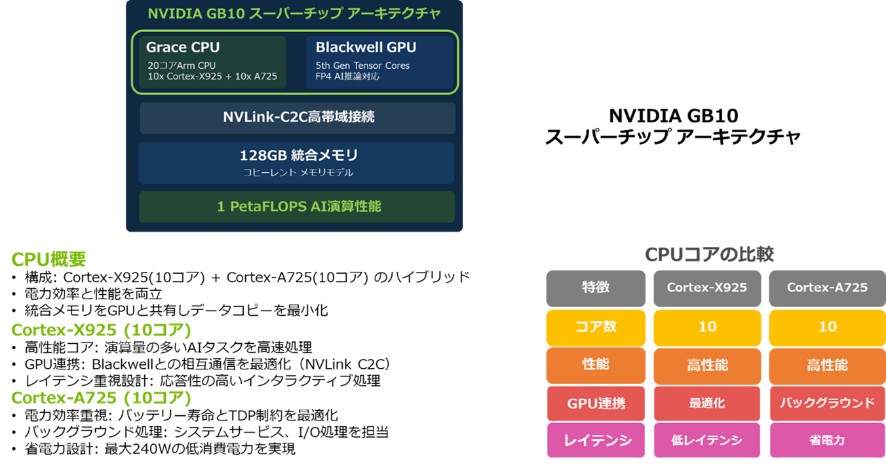
・CPU:20コアArm CPU(10Cortex-X925 + 10 Cortex-A725)を搭載
その中心となるのがGB10 Grace Blackwell Superchipです。このチップで重要な役割を果たすのが、CPUとGPUを高速接続するNVIDIA NVLink®-C2Cです。
NVLink-C2Cは、CPUであるGraceとGPUであるBlackwellをチップ間で接続し、これによって128GBの統合システムメモリをCPUとGPU間でコヒーレントに共有することを可能にしています。これにより、AIモデルのデータアクセス時の遅延を最小限に抑えられます。
その結果、大規模データセットを扱う際の効率も向上します。
これにより、従来のGPUではメモリが足りずに実行できなかった大規模なモデルをDGX Spark上で実行可能です。例えば、GPT-OSS-120Bのような約60GBのメモリを要するモデルでも、十分な余裕を持って動作させることができます。
メモリ帯域幅は最大273GB/sであり、これは最新のGPUであるNVIDIA RTX™ Pro 6000シリーズ(1,792GB/s)と比較すると約6分の1の値です。しかし、帯域幅自体は最新GPUより低いものの、NVLink-C2CによるCPU–GPU間の低レイテンシ共有メモリがその弱点を補っています。この仕組みにより、実効性能は大きく向上します。なお、メモリはオンボード統合のため増設は不可です。
- 10GbE イーサネット(RJ-45): 標準的なネットワーク接続
【高速クラスター接続】
- NVIDIA ConnectX®-7 Smart NIC(2x 200G QSFP):最大200Gbpsの高速通信
- 物理ポート:2x200G QSFP
- 用途:2台のDGX Spark間の直接接続によるメモリ拡張
クラスタリング機能:このConnectX-7 SmartNICを活用し、2台のDGX Sparkを直接接続することで、メモリ容量を256GBに拡張し、FP4形式で最大4,050億パラメータ規模のAIモデルに対応可能
I/O:USB TypeCポートを4つ(うち1つは電源供給に使用可能)、HDMI 2.1a(8K対応、マルチチャネル音声出力)を搭載
電力効率: 最大消費電力は240W。標準的な家庭用コンセントで動作する省電力設計
▼図5 GB10 SuperchipアーキテクチャとCPU概要
▼図6 DGX Spark背面イメージ

NVIDIAのドライバ、CUDA、Python、およびフルAIソフトウェアスタックがプリインストール済みで、箱から出してすぐに開発に取り掛かれます。これはDGX CloudやデータセンターのDGXシステムを支えるのと同様のエンタープライズグレードのソフトウェアアーキテクチャであり、ローカルで構築したワークフローを修正なしで大規模環境へシームレスに移行できる「クリーンなパス」をご提供します。
•NVIDIA Sync: Mac/Windows/Linuxに対応する接続ユーティリティで、SSHキー配布と接続を自動化し、VS Codeなど主要IDEとの連携を高速化
•豊富なPlaybooks: DGX Sparkでの動作検証済みのDockerイメージや、ステップバイステップのガイド(Playbooks)を提供
例として、Ollamaを使用したGPT-OSS 120Bの実行、Comfy UIでの画像生成、TensorRT LLMやNeMoを活用したファインチューニング、マルチエージェントチャットボットの構築などが挙げられます。
DGX Sparkの価値の再確認: DGX Sparkは、大容量メモリ(128GB)とBlackwellアーキテクチャを融合し、ローカル環境で大規模AI開発(2,000億パラメータ)を可能にした革新的なシステムです。
開発者にとっての意味: リソース待ち時間ゼロで、クラウド依存のコスト増やデータセキュリティの懸念を避けつつ、データセンター級のワークフローをデスクサイドで実現できます。
DGX Sparkは、これまで大規模なデータセンターや高価なクラウド環境がなければ実現できなかった AI 開発を、開発者一人ひとりのデスクサイドへと引き寄せる存在です。
GPU の空きを待つことも、クラウド費用を気にし続けることもなく、機密データを外に出す不安もありません。
「思いついたらすぐ試せる」「試した結果をすぐ改善できる」――
そんな当たり前の開発サイクルを、AI 開発の世界でも実現します。
DGX Sparkは、AI開発を特別な人や特別な環境だけのものから、誰もが現実的に取り組める日常的な開発作業へと変えていくための、最小にして最強のプラットフォームです。
本コラムの続きはこちら:
-[NVIDIA DGX Sparkとは?②~FP4×128GB統合メモリの実力~]
-[NVIDIA DGX Sparkとは?③ デスク上の“データセンター”を実現するネットワークとソフトウェア]
関連ページはこちら:
-[NVIDIA DGX Spark 製品ページ]
-[NVIDIA DGX Spark 専用のご購入・お問い合わせフォーム]
-[NVIDIA DGX Spark のよくある質問]
 公開日:
公開日:
最終更新日:
しかし今、この状況を根本から変える新しいデバイスが私たちのデスク上に登場しました。
それが、NVIDIA DGX Spark™です。
DGX Sparkは、AIの構築と実行のためにゼロから設計された新しいクラスのコンピューターであり、その登場は「パーソナルAIスーパーコンピューター」の時代の幕開けを告げています。
今回はDGX Sparkについての紹介や誕生秘話なども含めてご説明します。
1.DGX Sparkとは?-超小型スーパーコンピューターの正体
1-1.パーソナルAIスーパーコンピューターという新定義
- 従来のデータセンター規模のAIコンピュート能力を、デスクトップサイズのコンパクトな筐体に凝縮
- サイズと重量:150mm x 150mm x 50.5mm、重量は約1.2kg
~デスクトップAIコンピューティングの必要性~
生成AIモデルの規模と複雑さの増大により、ローカルシステムでの開発作業は困難を極めています。大規模モデルをローカルで扱うには、大量のメモリが必要です。
さらにプロトタイピングや推論には、高度なコンピューティング性能も求められます。企業、ソフトウェアプロバイダー、政府機関、スタートアップ企業、そして研究者がAI開発に注力するにつれ、AIコンピューティングリソースの必要性は高まり続けています。
デスク上の200B(2,000億) パラメータモデルDGX Sparkは、AIの構築と実行のためにゼロから設計された新しいクラスのコンピューターです。NVIDIA GB10 Grace Blackwellスーパーチップを搭載し、NVIDIA Grace Blackwellアーキテクチャをベースとし、最大1ペタフロップス(petaFLOPS)のAIパフォーマンスを実現し、大規模なAIワークロードに対応します。128GBの統合システムメモリにより、開発者は最大2,000億個のパラメータを持つモデルの実験、ファインチューニング、推論を行うことができます。 さらに、NVIDIA Connect-X™ネットワークにより、2台のDGX Sparkスーパーコンピューターを接続することで、 最大4050億個のパラメータを持つモデルでの推論が可能になります。
1-2.DGXシリーズの系譜と「誕生秘話」
DGX Sparkは、手のひらサイズで1PFLOPS級の性能を持つ「超小型AIスーパーコンピューター」であり、AI向けのスーパーコンピューターであるDGXシリーズの系譜でもあり、手軽にデスクトップで使えるようにしたワークステーションです。DGX Sparkの誕生は、AIモデルの巨大化とともに歩んできたDGXシリーズの系譜の延長にあります。
2016年、OpenAIがGPTシリーズの前身モデルの開発に用いた初代DGX-1は、当時のAI研究を支える象徴的なスーパーコンピューターでした。
AIモデルの規模は数年ごとに100倍のペースで拡大し、必要なコンピュートリソースも指数関数的に増加してきました。
▼図2 AI大規模化のマイルストーン
AIモデル巨大化の象徴であるDGX-1と、その性能をデスクトップサイズで実現したDGX Sparkは、対照的な存在です。
以下に両者の主要な仕様を比較します。
▼表1 仕様比較:NVIDIA DGX-1 vs NVIDIA DGX Spark
| 項目 | DGX-1(初代) | DGX Spark |
|---|---|---|
| アーキテクチャ | NVIDIA Pascal | NVIDIA Grace Blackwell |
| GPU | 8xNVIDIA Tesla P100 | NVIDIA Blackwellアーキテクチャ |
| CPU | 2xIntel Xeon E5-2698 v4(20コアx2/40コア) | 20コア Arm(10Cortex-X925+10 Cortex-A725) |
| GPUメモリ容量 | 16GB HBM2(1GPUあたり) | 128GB 統合メモリ(LPDDR5x)※GPUと共有 |
| GPUメモリ総容量 | 128GB(16GBx8GPU) | 128GB(システム全体で共有) |
| Tensor コア | 搭載なし | 第5世代 |
| データ形式 | FP32、FP64、FP16 | TF32、FP16、BF16、INT8、FP8、FP6、FP4 |
| RT コア | なし | 第4世代 |
| Tensor Performance | ― | 1petaFLOPS* |
| システムメモリ | 512GB DDR4(Xeon CPUメモリ) | 128GB LPDDR5x 統合システムメモリ |
| メモリインタフェース(GPU) | P100: 4096bit HBM2 | 256bit |
| メモリ帯域幅(GPU) | P100: 720GB/s | 最大273GB/s |
| ストレージ | 4x1.92TB SSD(RAID0/合計7.68TB) | 4TB NVMe M.2(SED対応) |
| USB | USB 3.0x3 | 4×USB TypeC |
| ネットワーク | 2x10GbE、4x100Gb/s InfiniBand(EDR) | 10GbEイーサネット、Wi-Fi 7 |
| NIC | Mellanox ConnectX-4(InfiniBand EDR) | ConnectX-7 NIC @200Gbps |
| Wi-Fi | なし | Wi-Fi 7 |
| Bluetooth | なし | Bluetooth 5.4 |
| Audio Output | なし | HDMI multichannel audio output |
| 消費電力 | 3200W(最大) | 240W |
| ディスプレイコネクタ | GPU に映像出力なし | 1xHDMI 2.1a |
| サイズ・重量 | 866x444x131mm(5U)/約60kg | 150x150x50.5mm/1.2kg |
| OS | NVIDIA DGX OS(Ubuntu ベース) | NVIDIA DGX OS |
| NVENC / NVDEC | なし | 1x/1x |
| 最大AIモデル規模 | 記載なし | 2,000億パラメータ |
2.DGX Sparkが生まれた背景 ―AI開発現場の「3つの制約」解決
ChatGPTやStable Diffusionの登場以来、AIモデルの知識量(パラメータ数)は爆発的に増大し、GPT-3は1,750億パラメータ、GPT-4は推定数兆パラメータ規模に達しています。図2で示しているように、モデルの規模は数年ごとに100倍のベースで増えてきており、これに伴い、必要なコンピュートリソース(GPU数、メモリ要件、電力消費)も指数関数的に増大し、学習コストは急増しています。
そこで今後の競争力のカギは、ローカルで高性能なコンピュートを確保することが求められています。
2-1.DGX Sparkが解決する「3つの制約」
従来のAI開発アプローチでは解決できなかった、開発現場の「3つの制約」をDGX Sparkは同時に解決するアプローチを提供できます。2-1-1.性能・リソースの制約
オンプレミス環境では、GPUリソースや専用ハードウェアの導入がボトルネックとなり、柔軟なAI活用が難しくなっています。特にGPUメモリの不足は深刻で、大規模モデルを実行できない最大の要因でした。そのため、多くの企業では数千万円〜数億円規模の投資が必要となっていました。加えて電力設備や保守費用などのコスト負担も強いられることになってしまいました。
それだけではなく、インフラチームのスキル・人手不足で運用も難しくなっています。
解決策:
DGX Sparkは、スモールスタートが可能なハードウェアであり、専用GPUリソースを即座に利用可能にして、プロトタイプやスモールスタートを可能にします。複雑な設定なしで、すぐに開発・検証が開始できます。
2-1-2.クラウドの制約
クラウドは手軽でありますが、利用が拡大するにつれてコストや性能面の制約が顕在化します。例えば、PoCで利用する分にはコストは安いですが、本番利用ではコストが跳ね上がってしまいます。また、オンプレミス環境ではないため、大容量データの転送がボトルネックになってしまうことがあり、また、クラウド環境においては、自社固有の要件に合わせづらく、無理やり合わせようとするとコストがかかってしまい、カスタマイズに制限を受けます。
解決策:
DGX Sparkを導入して、ローカル処理により低遅延を実現し、クラウド依存を減らして予算を安定化させ、長期的なTCO(総所有コスト)の削減に貢献します。オンプレミスに近い自由度でワークロードを最適化可能です。
2-1-3.セキュリティの制約
機密データを扱う業界では、クラウド利用に伴うリスクや規制遵守の課題が避けられません。データ主権の観点から、機密データを海外クラウドに預けづらいと考える企業も多く、クラウド利用における情報漏洩リスクを懸念する声もあります。
また日本企業では、業界ごとの法規制により、厳しい運用要件が求められるケースもあります。
解決策:
DGX Sparkは、オンプレミス完結にデータ処理を可能にし、機密データを外部に出さずに安全に利用できます。特に金融、医療、製造などの規制産業での活用に最適です。
▼図3 開発現場の3つの制約
3.DGX Sparkの心臓部 GB10 Grace Blackwell Superchipの技術詳細
DGX Sparkの核となるのは、デスクトップフォームファクター向けに最適化されたNVIDIA GB10 Grace Blackwell Superchipです。この章ではNVIDIA DGX Sparkの詳細内容についてご説明します。▼表2 DGX Spark 詳細スペック
| 項目 | 内容 |
|---|---|
| アーキテクチャ | NVIDIA Grace Blackwell |
| GPU | NVIDIA Blackwell |
| CPU | 20コア Arm(10Cortex-X925 + 10Cortex-A-725) |
| Tensor コア | 第5世代 |
| データ形式 | TF32、FP16、BF16、INT8、FP8、FP6、FP4 |
| RT コア | 第4世代 |
| Tensor Performance | 1petaFLOPS * |
| システムメモリ | 128GB LPDDR5x 統合システムメモリ |
| メモリインタフェース | 256bit |
| メモリ帯域幅 | 最大273GB/s |
| ストレージ | 4TB NVMe M.2(SED対応) |
| USB | 4×USB TypeC |
| ネットワーク | 10GbEイーサネット、Wi-Fi 7 |
| NIC | ConnectX-7 NIC @200Gbps |
| Wi-Fi | Wi-Fi 7 |
| Bluetooth | Bluetooth 5.4 |
| Audio Output | HDMI multichannel audio output |
| 消費電力 | 240W |
| ディスプレイコネクタ | 1×HDMI 2.1a |
| サイズ・重量 | 150×150×50.5mm、1.2kg |
| NVENC / NVDEC | 1x/1x |
| 最大AIモデル規模 | 2,000億パラメータ |
▼図4 DGX Spark ハードウェア仕様
3-1.統合アーキテクチャと演算性能
・アーキテクチャ:NVIDIA Grace Blackwellアーキテクチャを採用・GPU:Blackwell GPU(第5世代 Tensor コア搭載)
・Tensor Performance: FP4精度(スパース性特性を用いた理論値)で最大1petaFLOPS(1,000 AI TOPS)の性能を実現
・CPU:20コアArm CPU(10Cortex-X925 + 10 Cortex-A725)を搭載
3-2.NVLink-C2CによるCPUとGPUの緊密な統合
DGX Sparkは、AIスーパーコンピューティング向けに設計されたアーキテクチャを採用しています。その中心となるのがGB10 Grace Blackwell Superchipです。このチップで重要な役割を果たすのが、CPUとGPUを高速接続するNVIDIA NVLink®-C2Cです。
NVLink-C2Cは、CPUであるGraceとGPUであるBlackwellをチップ間で接続し、これによって128GBの統合システムメモリをCPUとGPU間でコヒーレントに共有することを可能にしています。これにより、AIモデルのデータアクセス時の遅延を最小限に抑えられます。
その結果、大規模データセットを扱う際の効率も向上します。
3-3.決定的な強み:128GB統合システムメモリ
DGX Sparkの大きな価値のひとつは、128GBの統合システムメモリにあります。128GB LPDDR5xのコヒーレント統合システムメモリを搭載しており、CPUとGPUがすべてのシステムメモリにアクセス可能です。これにより、従来のGPUではメモリが足りずに実行できなかった大規模なモデルをDGX Spark上で実行可能です。例えば、GPT-OSS-120Bのような約60GBのメモリを要するモデルでも、十分な余裕を持って動作させることができます。
メモリ帯域幅は最大273GB/sであり、これは最新のGPUであるNVIDIA RTX™ Pro 6000シリーズ(1,792GB/s)と比較すると約6分の1の値です。しかし、帯域幅自体は最新GPUより低いものの、NVLink-C2CによるCPU–GPU間の低レイテンシ共有メモリがその弱点を補っています。この仕組みにより、実効性能は大きく向上します。なお、メモリはオンボード統合のため増設は不可です。
3-4.接続性と拡張性
ネットワーク:一般的なネットワーク接続- 10GbE イーサネット(RJ-45): 標準的なネットワーク接続
【高速クラスター接続】
- NVIDIA ConnectX®-7 Smart NIC(2x 200G QSFP):最大200Gbpsの高速通信
- 物理ポート:2x200G QSFP
- 用途:2台のDGX Spark間の直接接続によるメモリ拡張
クラスタリング機能:このConnectX-7 SmartNICを活用し、2台のDGX Sparkを直接接続することで、メモリ容量を256GBに拡張し、FP4形式で最大4,050億パラメータ規模のAIモデルに対応可能
I/O:USB TypeCポートを4つ(うち1つは電源供給に使用可能)、HDMI 2.1a(8K対応、マルチチャネル音声出力)を搭載
電力効率: 最大消費電力は240W。標準的な家庭用コンセントで動作する省電力設計
▼図5 GB10 SuperchipアーキテクチャとCPU概要
▼図6 DGX Spark背面イメージ
4.箱から出してすぐに使える「AI開発環境」の実現
DGX Sparkは、ハードウェアだけでなく、AI開発者が直面する「ソフトウェア環境構築の負担」を解消するために、統合されたAIソフトウェアスタックを提供します。4-1.DGX OSと統一された基盤
OSとして、UbuntuベースのNVIDIA DGX OSが採用されています。NVIDIAのドライバ、CUDA、Python、およびフルAIソフトウェアスタックがプリインストール済みで、箱から出してすぐに開発に取り掛かれます。これはDGX CloudやデータセンターのDGXシステムを支えるのと同様のエンタープライズグレードのソフトウェアアーキテクチャであり、ローカルで構築したワークフローを修正なしで大規模環境へシームレスに移行できる「クリーンなパス」をご提供します。
4-2.開発を加速するツール群とPlaybooks
•DGX Dashboard: GPUやCPUの利用状況をグラフィカルに監視し、ブラウザベースの JupyterLabを起動できるハブ機能を提供•NVIDIA Sync: Mac/Windows/Linuxに対応する接続ユーティリティで、SSHキー配布と接続を自動化し、VS Codeなど主要IDEとの連携を高速化
•豊富なPlaybooks: DGX Sparkでの動作検証済みのDockerイメージや、ステップバイステップのガイド(Playbooks)を提供
例として、Ollamaを使用したGPT-OSS 120Bの実行、Comfy UIでの画像生成、TensorRT LLMやNeMoを活用したファインチューニング、マルチエージェントチャットボットの構築などが挙げられます。
5.まとめ
ここまで話してきた内容についてまとめます。DGX Sparkの価値の再確認: DGX Sparkは、大容量メモリ(128GB)とBlackwellアーキテクチャを融合し、ローカル環境で大規模AI開発(2,000億パラメータ)を可能にした革新的なシステムです。
開発者にとっての意味: リソース待ち時間ゼロで、クラウド依存のコスト増やデータセキュリティの懸念を避けつつ、データセンター級のワークフローをデスクサイドで実現できます。
DGX Sparkは、これまで大規模なデータセンターや高価なクラウド環境がなければ実現できなかった AI 開発を、開発者一人ひとりのデスクサイドへと引き寄せる存在です。
GPU の空きを待つことも、クラウド費用を気にし続けることもなく、機密データを外に出す不安もありません。
「思いついたらすぐ試せる」「試した結果をすぐ改善できる」――
そんな当たり前の開発サイクルを、AI 開発の世界でも実現します。
DGX Sparkは、AI開発を特別な人や特別な環境だけのものから、誰もが現実的に取り組める日常的な開発作業へと変えていくための、最小にして最強のプラットフォームです。
本コラムの続きはこちら:
-[NVIDIA DGX Sparkとは?②~FP4×128GB統合メモリの実力~]
-[NVIDIA DGX Sparkとは?③ デスク上の“データセンター”を実現するネットワークとソフトウェア]
関連ページはこちら:
-[NVIDIA DGX Spark 製品ページ]
-[NVIDIA DGX Spark 専用のご購入・お問い合わせフォーム]
-[NVIDIA DGX Spark のよくある質問]
筆者プロフィール
小宮 敏博(こみや としひろ)
菱洋エレクトロ株式会社|ソリューション事業本部 ソリューション技術部 営業技術G
経歴:KDDIで約8年システムエンジニアを経験後、ストレージベンダー・ソフトウェアベンダー・サーバーベンダーにてプリセールス、仮想化ソリューション、HCIビジネスの事業開発に従事。
2022年から株式会社トゥモロー・ネットにてセールスエンジニアリング部門長およびソリューション/AIビジネス開発に従事。主にNVIDIA 商材を取り扱っていた。
2025年からは現職。菱洋での実績は・・・NVIDIA AI EnterpriseとNVIDIA DGX Spark™をやっています!
専門分野:仮想化(VMware / Nutanix)関連、NVIDIA AI Enterprise / DGX Spark / LLM推論 / AIインフラ(Cuda / Docker / Kubernetes / その他)など
現場目線で、GPU×生成AIの実務ノウハウをわかりやすく発信します。
#NVIDIA #nvidiaaienterprise #LLM推論 #dgxspark #GPU #aiblog
最終更新日:




