

目次
1.はじめに
大規模な分散学習や高性能コンピューティング(HPC)では、ノード間のデータ転送レイテンシがボトルネックになりがちです。NVIDIAのGPUDirect RDMAは、GPUメモリとインフィニバンド(Host Channel Adapter、以下HCA)やネットワークアダプタ(NIC)を直接つなぎ、ホストメモリを介さないゼロコピー転送を実現しています。長らくLinuxのカーネルモジュール方式(nvidia_peermem)が使われてきましたが、最近ではLinux標準機構であるDMA-BUFを用いた構成ができるようになっています。
本稿では、移行背景、必要要件、設定・検証手順を実務目線で整理します。
2.技術概要 — GPUDirect/GPUDirect RDMAの仕組み
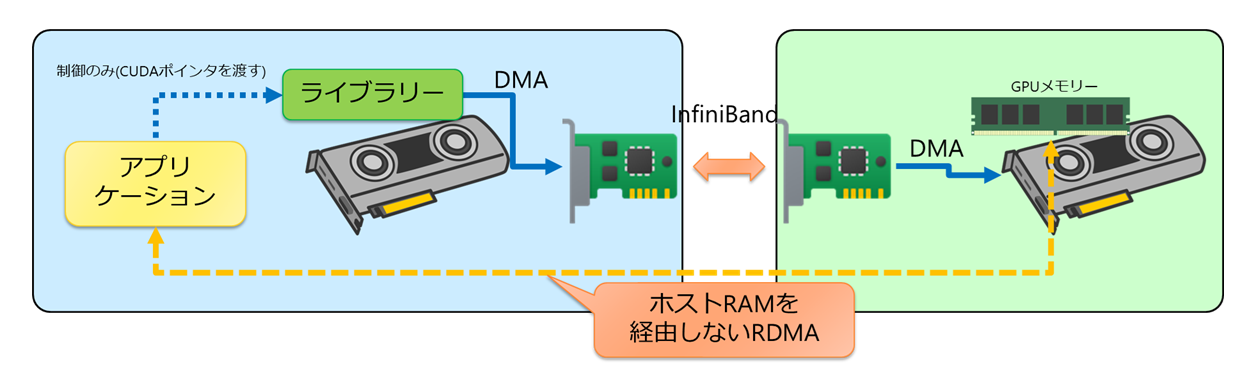
NVIDIA GPUDirect®は、GPUメモリと他デバイス間のデータパスからCPUコピーを排除する技術群の総称です。特にGPUDirect RDMAでは、HCAが他ノードを含むリモートGPUメモリへ、ホストメモリを経由せずに直接DMA(Direct Memory Access)できるようになります。アプリケーション側はCUDA®ポインタを通信ライブラリ(例:NCCL)へ渡すだけで、ライブラリがHCAを利用してGPUメモリ間のゼロコピー転送を実行します。GPUDirectは、CPUを経由する青い線ではなく、データを赤い線のように直接コピーします。
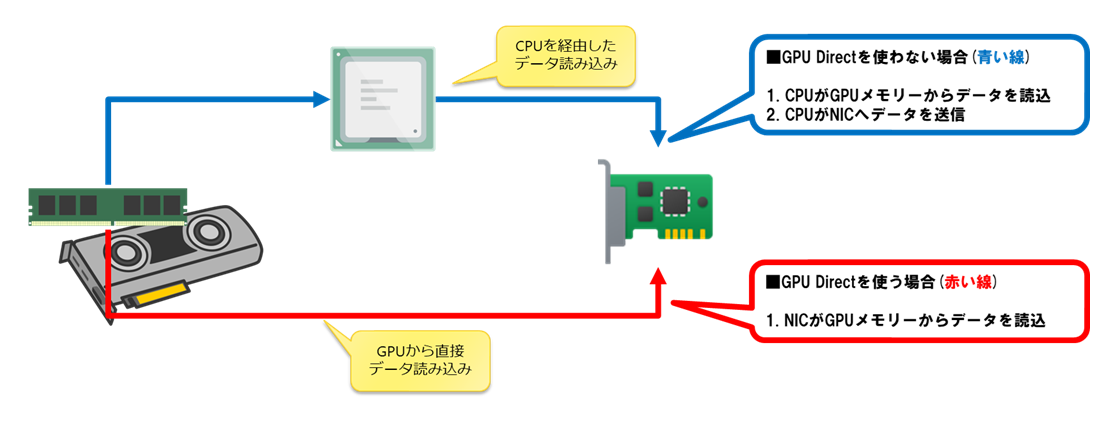
さらにGPUDirect RDMAでは、これを別ノードにまで拡張し、CPUを介さずデータをGPU間でコピーすることができるようになります。
3.なぜDMA-BUFなのか
歴史的には、専用カーネルモジュール(nvidia_peermem)を導入し、HCAとGPUを連携させるアプローチが取られてきました。しかし、モジュールのコンパイル・整合性維持・ディストリ間の差分吸収といった運用コストが高く、2025年の現在はLinux標準のDMA-BUFを活用する方式が推奨となっています。DMA-BUFはカーネル5.12以降で成熟が進み、ドライバ依存性を抑えつつ標準機構として運用しやすいメリットがあります。Linuxで標準的に組み込まれている機構なので安定していて、カーネルアップデートを気にすることなく利用できます。ただし、以下の要件にもあるとおり、LinuxのOSのバージョン、GPUドライバーやCUDA®対応バージョン、対応しているGPU等、幾つか注意点があります。
4.要件一覧
以下はDMA-BUF方式とレガシー(nvidia_peermem)方式の要件を比較したものです。新規構築・リプレースではDMA-BUFを前提とするのがよいでしょう。| テクノロジー | DMA-BUF | レガシーKernelモジュール(nvidia_peermem) |
|---|---|---|
| GPUドライバー | オープンカーネルモジュールドライバが必要 | サポートされているすべてのドライバー |
| CUDA | CUDA 11.7以上 | 最小バージョンなし |
| GPU | Turing以降のデータセンターGPU/Quadro RTX/NVIDIA RTX™ GPU | すべてのデータセンター/Quadro RTX/RTX GPU |
| ネットワークドライバー | MLNX_OFEDまたはDOCA-OFEDはオプション | MLNX_OFEDまたはDOCA-OFEDが必要 |
| Linuxカーネル | 5.12以上 | 最小バージョンなし |
5.前提条件
以下のような前提条件があります。InfiniBandではなく、EthernetのRoCEでも対応可能ですが、菱洋エレクトロでは確認しておりません。- Kernel:5.15+(Ubuntu 22.04 LTS以降)
- ドライバ:NVIDIAオープンカーネルモジュールドライバ(DMA-BUF要件)
- CUDA:11.7以上(運用上は12系が一般的)
- ネットワーク:InfiniBand(Connect-X4以降(mlx5系))
6.設定手順 — IOMMU推奨設定と再起動
DMA-BUFによるGPUDirect RDMAは追加設定が少ない点が利点ですが、IOMMUのパススルー設定が推奨です。以下はIntelプラットフォームでの例です(GRUB編集→反映→再起動を行ってください)。sudo sed -i 's/^GRUB_CMDLINE_LINUX="/GRUB_CMDLINE_LINUX="intel_iommu=on iommu=pt /' /etc/default/grub
sudo update-grub
sudo reboot
再起動後の確認例:
cat /proc/cmdline | tr ' ' '\n' | grep -E '(iommu|intel_iommu)'
uname -r
7.GPUDirect RDMAの帯域試験
正しく設定できているか、チェックするにはperftestを利用するのが一番簡単です。GPUDirect RDMAをテストするには、DMA-BUFに対応しているperftestのバージョン6.26以降が必要となります。Ubuntu 24.04のperftestはバージョン6.25なので、GitHubから最新版(25.07※)をダウンロードしてコンパイルする必要があります。
※補足:GitHubではリリース名がperftest-25.07.0-0.104となっていますが、これがバージョン6.26になります。
7-1.perftestをコンパイル
- ビルド用のパッケージを導入
ビルドに必要なパッケージを導入します。
sudo apt install -y build-essential autoconf automake libtool \
libibverbs-dev librdmacm-dev libnuma-dev pkg-config git libpci-dev - git cloneしてコンパイル
git clone https://github.com/linux-rdma/perftest.git
cd perftest
./autogen.sh
./configure
make -j"$(nproc)"
7-2.perftestで帯域試験
1.待ち受け側待ち受け側で以下のコマンドを実行します。実行パスはコンパイルしたディレクトリです。
./ib_write_bw -d mlx5_4 -a -F --report_gbits -q 1 --use_cuda=0 --use_cuda_dmabuf
-d mlx5_4はInfiniBandのポートを指定しています。
--use_cuda=0は、使用するGPUを指定しています。
--use_cuda_dmabufは、DMA-BUFの利用を指定しています。
2.送信側
送信側で以下のコマンドを実行します。実行パスはコンパイルしたディレクトリです。
./ib_write_bw -d mlx5_0 -i 1 -q 1 -a --report_gbits --use_cuda=0 --use_cuda_dmabuf <待ち受け側IPアドレス>
送信側のオプションは待ち受け側と同様ですが、--use_cuda_dmabufの後に待ち受け側のIPアドレス(IPoIB)を指定します。
8.注意 — GPUDirect StorageとのIOMMU推奨の相違
GDS(GPUDirect Storage)では、IOMMUは無効化(iommu=off)が推奨されています。ネットワーク(RDMA)中心のワークロードとストレージ中心のワークロードを同一イメージで併用する場合、起動プロファイルの分離やブートローダエントリの使い分けを検討してください。参考: GPUDirect Storage Installation and Troubleshooting Guide
※外部リンクに飛びます
9.まとめ
DMA-BUFベースのGPUDirect RDMAは、標準機構に基づく実装で運用の複雑性を抑えつつ、ゼロコピー転送による性能メリットを享受できます。まずは以下のステップでPoCを進めるとスムーズです。- 対象ノードのカーネル/ドライバ/CUDAを棚卸し(DMA-BUF要件充足の確認)
- IOMMU設定を適用し、
nvidia_peermem非ロードを確認 - NCCL等でGPU間通信ベンチマークを取得(帯域・レイテンシのベースライン化)
- カーネル更新やドライバ更新のチェンジ管理(検証→段階展開)
関連ページはこちら:
-[マルチインスタンスGPU(MIG)とは?仕組みや注意事項・実務手順もご紹介]
-[GPUドライバーとは?NVIDIA GPUドライバーを徹底解説]
-[NVIDIA DGX Sparkとは?~超小型スパコンの誕生秘話~ スペックや強みもご紹介]
-[NVIDIA DGX Sparkとは?②~FP4×128GB統合メモリの実力~]]
-[NVIDIA DGX Sparkとは?③ デスク上の“データセンター”を実現するネットワークとソフトウェア]
筆者プロフィール

矢野 哲朗(やの てつろう)
株式会社スタイルズ(菱洋エレクトログループ会社)
経歴:Kubernetesを中心としたクラウドネイティブ基盤の構築・支援を専門とし、株式会社スタイルズでオープンソースを軸に20年以上インフラに携わる。
Edge/AI分野でのGPU活用にも注力中。
専門分野:Kubernetes/Rancherによるクラウドネイティブ基盤構築、GPUを活用したEdge・AI案件の技術支援など
現場で得た知見をもとに、クラウドネイティブやEdge/GPU/AI技術をわかりやすく解説します。
#Kubernetes #CloudNative #EdgeComputing #GPU #Rancher #Nextcloud
公開日:
最終更新日:




