

目次
まだ第1弾を読んでいない方は、先に第1弾のコラム「NVIDIA DGX Sparkとは?~超小型スパコンの誕生秘話~ スペックや強みもご紹介」の記事をご覧いただくとスムーズにご理解いただけます。
第1弾では、NVIDIA DGX Spark™がどのような背景で誕生し、なぜ“パーソナルAIスーパーコンピューター”と呼ぶにふさわしいのか、その全体像と思想についてご紹介しました。
AIモデルの巨大化、クラウド依存によるコスト・パフォーマンスの限界、そしてローカルで高速に試せる環境の必要性――こうした文脈の中で、手のひらサイズで1PFLOPS級の性能を持ち、AI開発の民主化を進める新たな基盤としてDGX Sparkが生まれたことを解説しました。
しかし、DGX Sparkを“単なる高性能な小型マシン”として捉えると、その真価の多くを見落としてしまいます。
特に、AI開発者にとってどれだけ大きなモデルをローカルで扱えるかは、生産性と実験スピードを左右する最重要要素であり、その鍵を握っているのが128GBの統合メモリとFP4/疎化(Sparsity) による効率化設計です。
そこで本稿(第2弾)では、DGX Sparkのスペック全体の中でも“中心的役割”を果たすメモリ・帯域幅・低精度化(FP4)に焦点を当て、実際のユースケースを交えながら 「なぜこの小さな筐体で200B級モデルが動くのか」について徹底的に深掘りしていきます。
1.DGX Sparkの核心的優位性 — 128GB統合メモリの真実
DGX Sparkの最大の差別化要因は、CPUとGPUがコヒーレントにアクセス可能な128GB LPDDR5x統合システムメモリを搭載している点にあります。1-1.メモリ容量のメリットと従来の制約の解消
大規模モデルの実行可能性: 単一のDGX Sparkは、最大2,000億パラメータ規模のAIモデルの推論や、700億パラメータ規模のモデルのファインチューニングをローカル環境で実行できます。実証されたユースケース: 約60GB程度のメモリを必要とするGPT-OSS 120Bのような大規模モデルも、DGX Spark上で余裕をもって動作させることが可能です。さらに、拡散モデル(Flux)のファインチューニングなど、GPUメモリを110GB近く消費するような計算集約型のワークロードも実行可能であると実証されています。(※1)
(※1) 参照URL:https://build.nvidia.com/spark/flux-finetuning
マルチエージェントシステムの基盤: 複数の大規模モデル(例:GPT-OSS 120B、DeepSeek Coder 6.7B、Qwen 2.5 VL 7B)を同時にメモリにロードし協調動作させるマルチエージェントチャットボットシステムを構築でき、このシステムは実測で89GBから110GBのメモリを使用しています。(※2)
(※2) 参照URL:https://build.nvidia.com/spark/multi-agent-chatbot
▼図1 AI開発者/プロトタイプ作成
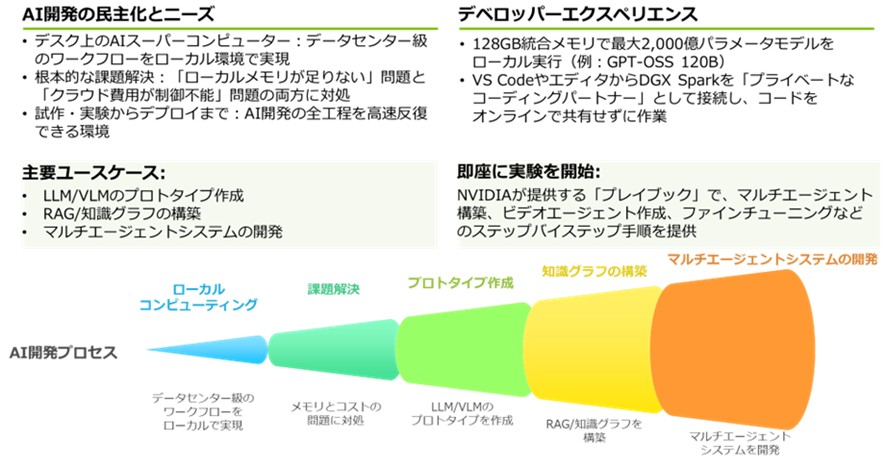
1-2.128GBと100GBの現実:OS/システムメモリのオーバーヘッド
DGX Sparkのシステムメモリは合計128GBですが、これはCPUとGPUで共有される統合メモリです。利用可能メモリの制約: 実際にAIワークロードやモデルのパラメータに使用できるメモリ容量は、OS(NVIDIA DGX OS)やシステムが使用するオーバーヘッドを考慮すると、約100GB程度となり、128GBすべてをGPUのリソースとして利用することはできないと考えられます。
▼図2 AIモデルサイズとメモリ容量の関係(NVIDIA社 提供資料)
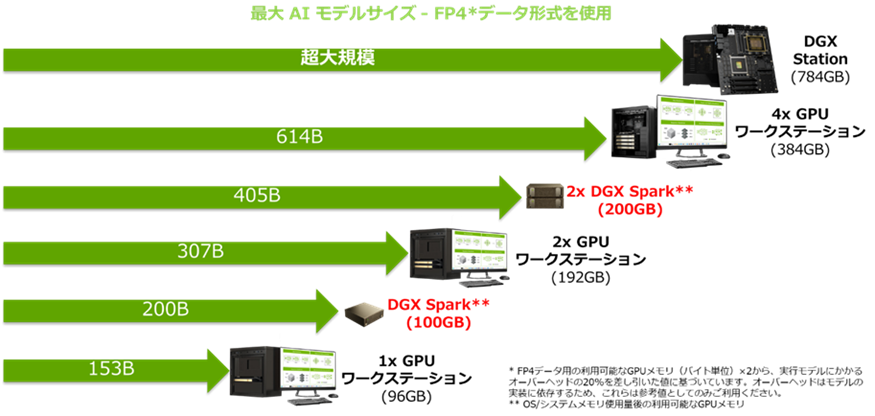
図2は、利用可能なメモリ量が OS やシステムによるオーバーヘッドでどの程度減少するかを視覚的に示しています。
モデルサイズの計算: モデルが最大200Bパラメータに対応します。(※NVIDIA社資料による)
2.性能とメモリ効率の鍵 — FP4スパース化の戦略
DGX SparkのGB10 Superchipは、理論上の最大AI演算性能として1PFLOPS相当すなわち 1,000 AI TOPS(テラオペレーション/秒)を実現しますが、これはFP4精度とスパース化(Sparsity)を活用したスパース化の特性を組み合わせた理論値です。※DGX Sparkの最大AI演算性能が最大1petaFLOPS(1,000 AI TOPS)であること、およびスパース化については、第1弾のコラム記事でも触れていますのでご参照ください。
定義:AIモデルやデータにおいて、多くの要素がほとんど寄与せず、少数の要素だけが意味を持つという特性(スパース化)を指します。
加速のメカニズム: スパース化を利用して、多くの「0」の演算をスキップすることで、理論上の高速化を可能にします。
性能についての留意点: この1PFLOPS は、スパース性機能が最大限発揮された場合の理論値です。 スパース化(Sparsity)による性能向上は、ワークロードがこの特定の条件に最適化されているかに大きく依存します。したがって、実際のワークロードにおいてこの性能を常に維持できるわけではありません。
今回はスパース化についてわかりやすいイメージで説明します。
2-1.スパース化 (疎化)とは
直感的に理解できるようにモノにたとえて説明します。導入:データ=家財道具
まずは、AIの学習データを「家にある大量のモノ」に例えます。
AIにデータを学習させるプロセスは、「引っ越し」に似ています。 私たちの部屋(データセット)には、毎日使う大切な家具もあれば、いつか使うかもしれない雑貨、あるいは二度と使わないようなゴミ(ノイズ)まで、あらゆるものが溢れています。
▼図3 AIにデータを学習させるプロセスを引っ越しに例えると
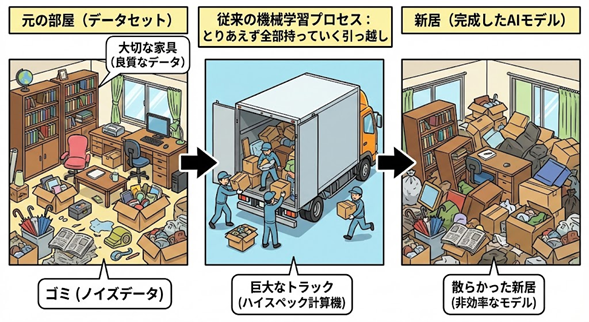
図3は、学習データを家財道具に見立て、スパース化の概念を直感的に理解できるように示したものです。
展開:スパース化(疎化)=「コスト制限」付きの荷造り
ここで、スパース化【L1正則化などの手法(※詳細は後述)】を導入します。これは「制約」を与えることです。
そこで登場するのが「スパース化(Sparse Modeling)」という考え方です。これは、引っ越し業者から次のように言われた状態だと想像してください。
「お客様、トラックが軽トラック1台しかありません。本当に生活に必要なものだけを選んでください。載せられないものは、すべて捨てて(ゼロにして)いきます」
この厳しい制約(ペナルティ)があることで、私たちは真剣に選別を始めます。
・ベッド(重要な要因)→ 持っていく
・冷蔵庫(重要な要因)→ 持っていく
・10年前の雑誌の束(ノイズ)→ 捨てる(重み0)
・壊れたおもちゃ(ノイズ)→ 捨てる(重み0)
従来のL2正則化(※3)などによる“圧縮”は、いわば「布団圧縮袋を使って、すべての荷物を小さくして持っていく」ことでした。モノの数は減りません。 一方、スパース化は「持っていかない」という決断(係数を完全にゼロにする)をします。ここが決定的な違いです。
▼図4 スパース化(L1正則化)を導入した場合
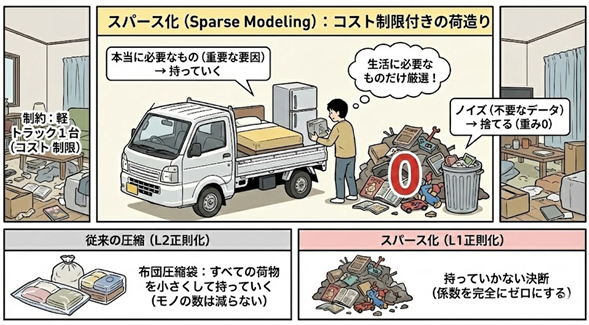
(※3) 補足:スパース化の仕組みについて
AIにペナルティ(罰則)を与えるルールを教えることにより、ゼロにする内容を決めることが重要です。
L2正則化(よくある手法):「全員、少しずつ遠慮してください」→ 全員の値が小さくなるが、ゼロにはならない(全員残る)。
ここでは、荷物を小さくすることによりモノを小さくしているが、数は減っていない
L1正則化(スパース化):「全員の持ち点の合計(絶対値)に上限を設けます」→ 影響力の低い人は強制的にゼロになり、退場させられる。
ここでは、荷物を捨てる(ゼロにする)ことで、モノそのものを減らしている
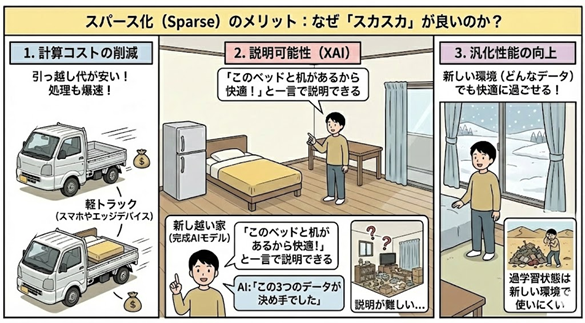
メリットの解説:なぜ「スカスカ」が良いのか?
「スパース(Sparse)」であることが、なぜAIにとって良いのかを解説します。
荷物を極限まで減らして(スパース化して)引っ越した新居は、どうなるでしょうか?
1.引っ越し代が安い(計算コストの削減)
荷物が少ないので、軽トラック(スマホやエッジデバイスなどの非力なマシン)でも十分に動きます。処理も爆速です。
2.何がどこにあるか一目瞭然(説明可能性・XAI※Explainable AI)
モノが溢れた部屋では「なぜ快適なのか」を説明するのは難しいですが、モノが少ない部屋なら「このソファがあるから快適なのです」と一言で説明できます。 AIにおいても同様で、「なぜこの予測結果になったのか?」という問いに対し、「この3つのデータ(家具)が決め手でした」と人間にはっきり説明できるようになります。
3.新しい生活に馴染みやすい(汎化性能の向上)
前の家のゴミまで持ってきた部屋(過学習状態)は、新しい環境では使いにくいものです。本質的に必要なものだけを持ってきた部屋は、どんな環境でも快適に過ごせます。
▼図5 スパース化であることがAIによって良いことの説明
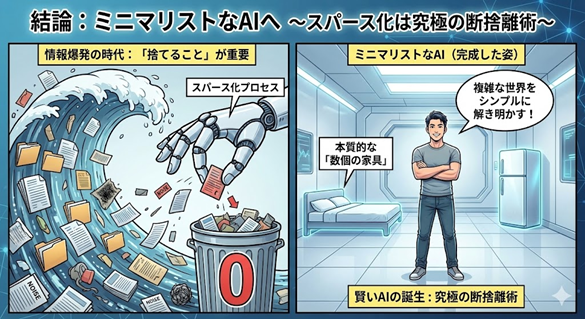
結論:ミニマリストなAIへ
情報爆発の時代、データは集めることよりも「捨てること」の方が難しく、重要になってきています。 複雑な現象の中から、本質的な「数個の家具」だけを見つけ出し、あとは潔く手放す。スパース化とは、AIにおける「究極の断捨離術」なのです。
▼図6 ミニマリストなAIのイメージ
2-2.メモリ帯域幅消費を低減しスループット向上
「Blackwell Transformer Engineでは、FP4 Tensorコアによって演算効率が向上し、HBMのパラメータ帯域幅を活かすことで実効メモリ帯域が増加します。これにより、GPUあたりで処理可能なモデルの規模(model capability)が拡張されます。」と説明しており、この説明は、FP4によってビット幅を削減し、その結果として実効メモリ帯域を拡張してスループットを向上させるというBlackwellの構造的特徴を示しています。参照URL:https://docs.nvidia.com/multi-node-nvlink-systems/multi-node-tuning-guide/overview.html
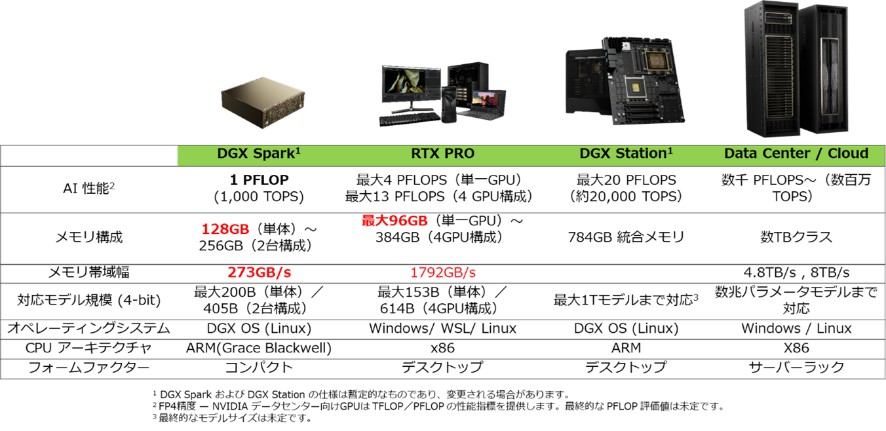
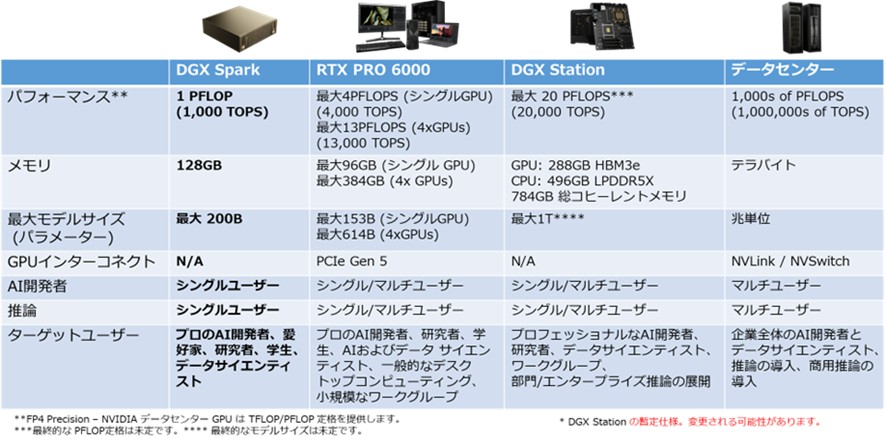
以下でDGX SparkのメモリスペックおよびNVIDIA製他のGPUについて説明します。図7では、DGX Sparkの主要仕様を赤字で示しています。
メモリ帯域幅の制約: DGX Sparkのメモリ帯域幅は最大273GB/sであり、これはハイエンドのディスクリートGPU(RTX Pro 6000の1,792 GB/s)と比較して約6分の1と低い値です。(この比較グラフは第1弾ブログでも紹介しています。)
▼図7 NVIDIA AI開発プラットフォーム:ハードウェア仕様比較(NVIDIA社 提供資料)
FP4の役割: Blackwellアーキテクチャでは、FP4(NVFP4)によるビット幅削減を前提としたデータ表現を採用しており、その結果として実効的なメモリ帯域が拡張され、スループットが向上する構造になっています。
NVIDIA Developer Technical Blog : Introducing NVFP4 for Efficient and Accurate Low-Precision Inference:https://developer.nvidia.com/blog/introducing-nvfp4-for-efficient-and-accurate-low-precision-inference/
概要:
・NVFP4は、NVIDIAの最新GPUマイクロアーキテクチャBlackwell向けに導入された「4bit浮動小数点(FP4)フォーマット」です。特に推論(inference)向けに最適化された低精度フォーマットであり、従来の高精度(FP16/FP8など)よりも極端にビット数を落としつつ、AIモデル(特に大規模言語モデル=LLM)の推論(inference)を効率化する目的で設計されています。
・特に、NVFP4は「4ビット(1サイン+2指数+1仮数)」という標準的なミニフロート構造を取りつつ、 “2段階のスケーリング(two-level micro-block scaling)を導入することで、FP4の弱点である 表現範囲(dynamic range)と量子化誤差の問題を大幅に改善しています。
具体的には
1. まず、16要素ごとの「マイクロブロック(micro-block)」に対し、FP8(E4M3)のスケール係数(scale factor)を共有。
2. さらに、テンソル全体(あるいは大きな範囲)に対してFP32の全体スケールを適用。
この構造によって、単純なFP4よりも量子化誤差(quantization error) を抑えつつ、メモリ容量・メモリ帯域・演算量を大幅に削減し、推論性能を向上させることが可能になります。
【主なメリット―メモリ効率・速度・消費電力など】
・メモリ効率の面では、NVFP4を使うことで従来のFP16と比べて約3.5倍のメモリ削減、またFP8と比べても約1.8倍の削減が可能、というデータが示されています。
・推論スループット(throughput)やエネルギー効率も大幅に改善される見込みです。記事中では、低精度化+小メモリ化+Blackwellの第5世代Tensorコアによるハードウェア最適化により、通例の推論コスト・トークンあたり消費電力を大きく削減できると説明されています。
また、精度(モデルの「知性」「タスク性能」)の劣化は非常に小さい — あるモデルを使った評価では、FP8→NVFP4への量子化で、言語モデリング系ベンチマークにおいて多くのテストで誤差 ≦1%、あるいはごく僅かな低下で済んでいる例が報告されています。
ここで重要なのは、4bit/超低精度でも実用可能なのかです。
NVFP4が単なる“ビット削減”ではなく“実用的な低精度運用”を可能にしている理由は以下になります。
さらに、Blackwellアーキテクチャでは 「2:4構造化スパース性(Structured Sparsity)」 もハードウェアレベルでサポートされています。
これは「4つの重みのうち2つを必ずゼロにする」という制約を設けることで、モデルの重みを50%削減しつつ、Tensor Coreがそれを前提に高速化を行える仕組みです。
FP4やNVFP4と組み合わせることで、
◆メモリ帯域幅を削減します
◆計算量を削減します
◆スループットが向上します
を同時に実現し、Blackwell 世代の推論性能の重要な基盤となっています。
マイクロブロックごとのスケーリング:16要素という細かい単位でのスケール共有により、テンソル内でばらつきが大きい値(大きいもの・小さいもの混在)に対しても適応できる。これにより、単一の粗いスケール(例えば32要素ブロック+パワーオブ2スケール)を使った単純な量子化で起こりやすい “値の飽和/丸め誤差→精度劣化” を抑制。
二重スケール(micro-block + global): ローカルな値分布の調整(micro-block)に加え、テンソル全体のスケールをFP32で管理することで、ダイナミックレンジ(大きな値から小さな値まで)をほぼ失わず、かつ低ビット表現を保つ。
Blackwellのハードウェア支援: 第5世代Tensorコアにおいて、NVFP4を含む超低精度フォーマット(FP4など)をネイティブにサポート。これにより、量子化された重み・活性化のままで高速な行列演算(GEMM: General Matrix Multiply) が可能。
3.AI開発者にとってDGX Sparkの価値と「シングルユーザー」への最適化
DGX Sparkは、純粋な推論速度を追求するシステムではなく、AIの構築と実行のためにゼロから設計されたAI開発者向けシステムとして位置づけられています。▼図8 DGX Sparkの製品ポジショニング(NVIDIA社 提供資料)
3-1.シングルユーザー環境としての設計思想
開発者向けの位置づけ:DGX Sparkは、AI開発者、愛好家、研究者、学生、データサイエンティスト のための新しいクラスのコンピューターです。専用のコンピュートリソース:従来のデータセンターやクラウド環境では、他の競合するワークロードとスケジュール調整やリソースの取り合いが必要になりますが、DGX Sparkはデータセンターのコンピューティング能力の競合やクラウドインスタンスの費用なしで、自分専用のAIクラウドとして機能します。
▼図9 ローカル環境でのAI開発における課題
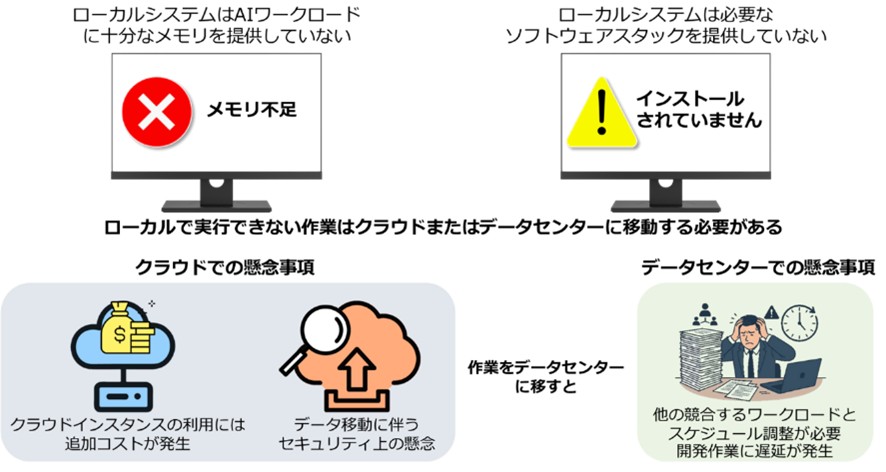
利用形態:DGX Sparkは、基本的には1人のユーザーが利用することができるデバイスです。これは、AI開発者にリソースの待ち時間ゼロで、クラウド依存のコスト増やデータセキュリティの懸念を避けつつ、作業を可能にするためです。
3-2.ローカルAI環境とプライベートなコーディングパートナー
シングルユーザーであることの最大の利点は、セキュリティと開発効率の最大化です。・プライバシーの確保
機密性の高いデータやコードを外部のクラウドに送ることなく、ローカル環境(オンプレミス)で処理を完結させることができます。これは規制産業などには最適です。
・従来のクラウド型AI支援コーディング環境
自身のラップトップやデスクトップ(Mac/Windows/Linux)からNVIDIA Syncユーティリティを通じて、DGX Sparkにリモート接続し、VS CodeなどのIDEと連携できます。この際、DGX Sparkをプライベートなコーディングパートナーとして利用することで、コードをオンラインで共有せずにAIアシスタントを活用できます。
▼図10 NVIDIA Syncについて
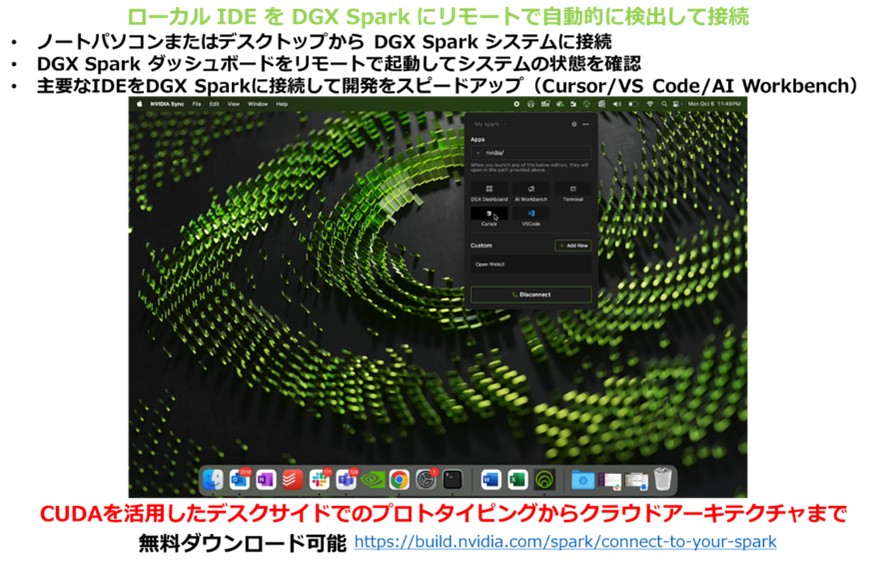
コンパニオンAI: DGX Sparkは、開発者が日常的に使用するラップトップやデスクトップを補完するコンパニオンAIとして機能し、AIワークロードをDGX Sparkにオフロードして、メインのデバイスで通常の生産性作業を続けることができます。
▼図11 データサイエンティストの役割とDGX Sparkとしての機能
3-3.ソフトウェアスタックによる開発の加速
ターンキーAI基盤: DGX Sparkには、AIの構築と実行のために必要なNVIDIA AIソフトウェアスタック(DGX OS、CUDA、TensorRT、Ollamaなど)がプリロードされており、環境構築の手間なしに即座に開発を開始できます。シームレスな拡張性: DGX Sparkで開発されたワークフローは、大規模なDGX CloudやデータセンターのDGXシステムへ、コード変更なしでシームレスに移行可能です。これは、開発者がAIワークフローをスケールアウトための明確なインフラ戦略を可能にします。
4.まとめ
ここまで話してきた内容についてまとめます。• DGX Sparkの価値の再確認
DGX Sparkは、128GB(実質100GB程度)の統合メモリとFP4スパース化技術を組み合わせ、ローカル環境で超大規模モデルの実行可能性とエンタープライズグレードのAI開発環境を両立させた、戦略的なシステムです。
• 開発者にとっての意味
リソース待ち時間ゼロで、クラウド依存のコスト増やデータセキュリティの懸念を避けつつ、データセンター級のワークフローをデスクサイドで実現する、シングルユーザーに最適化された最小にして最強のAIプラットフォームです。
これまで大規模モデルの活用は、豊富なクラウドリソースと複雑な運用を前提とした、限られた組織だけの世界でした。データを託すリスク、コストの不安定さ、そして思い通りに使えない環境——これらは開発者にとって避けられない制約でもありました。
DGX Sparkは、そうした前提を覆す存在です。
FP4 と疎性(Sparsity)による効率化により、限られた帯域でも“大規模モデルを現実的な性能で扱える”アーキテクチャを実現し、128GBの統合メモリは、クラウドに依存しない完全ローカルの大規模AI環境を可能にします。
さらに、VS Codeなど日常の開発環境とシームレスに連携できることで、「データを外に出さずに、安全に、そして自分のペースで開発できる」新しいワークフローを手元に取り戻すことができます。
リソース待ちのストレスやクラウドの制約から解放され、思考のスピードで試し、検証し、そのまま成果に変えられる。DGX Sparkは、開発者の生産性を根本から押し上げる“プライベートなAIパートナー”です。
クラウドに預けるかどうかを自分で選べる自由。自分専用の、安全で柔軟なAIインフラを持つという価値。
第1弾のコラムで触れた「AI開発環境を手元に取り戻す」というテーマは、ハードウェアの進化だけでなく、開発者が主体的に選択できる自由を取り戻すという意味でも重要です。
DGX Sparkは、そんな“AIを自分の手に取り戻す”ための最小にして最適なプラットフォームです。
本コラムの続きはこちら:
-[NVIDIA DGX Sparkとは?③ デスク上の“データセンター”を実現するネットワークとソフトウェア]
関連ページはこちら:
-[NVIDIA DGX Sparkとは?~超小型スパコンの誕生秘話~ スペックや強みもご紹介]
-[NVIDIA DGX Spark 製品ページ]
-[NVIDIA DGX Spark 専用のご購入・お問い合わせフォーム]
-[NVIDIA DGX Spark のよくある質問]
筆者プロフィール

小宮 敏博(こみや としひろ)
菱洋エレクトロ株式会社|ソリューション事業本部 ソリューション技術部 営業技術G
経歴:KDDIで約8年システムエンジニアを経験後、ストレージベンダー・ソフトウェアベンダー・サーバーベンダーにてプリセールス、仮想化ソリューション、HCIビジネスの事業開発に従事。
2022年から株式会社トゥモロー・ネットにてセールスエンジニアリング部門長およびソリューション/AIビジネス開発に従事。主にNVIDIA 商材を取り扱っていた。
2025年からは現職。菱洋での実績は・・・NVIDIA AI EnterpriseとNVIDIA DGX Spark™をやっています!
専門分野:仮想化(VMware / Nutanix)関連、NVIDIA AI Enterprise / DGX Spark / LLM推論 / AIインフラ(Cuda / Docker / Kubernetes / その他)など
現場目線で、GPU×生成AIの実務ノウハウをわかりやすく発信します。
#NVIDIA #nvidiaaienterprise #LLM推論 #dgxspark #GPU #aiblog
最終更新日:




