

目次
1. はじめに
近年、生成AIやHPC(High Performance Computing)の拡大により、1枚のGPUを複数の業務で安全かつ効率的に共有したいという要請が強まっています。NVIDIAのマルチインスタンスGPU(MIG)は、GPUをハードウェアレベルで分割し、各インスタンスに専用のメモリ(HBM: High Bandwidth Memory)、演算資源(SM: Streaming Multiprocessor、L2キャッシュ)、Copy Engine、帯域を割り当てることで、ワークロード間の干渉を抑えて、GPU演算のQoS(Quality of Service)を保証する技術です。
今回の技術コラムでは、MIGの基本から仕組み、対応世代、プロファイル例、そして実務での使い方までを簡潔にご紹介します。
2. マルチインスタンスGPU(MIG)とは
MIGは、NVIDIA Ampere世代から導入された仕組みで、1枚のGPUを複数の独立した"インスタンス"として扱えるようにするテクノロジーです。各インスタンスは専用のメモリ(HBM)や演算資源(SM/L2キャッシュなど)がハードウェア的に隔離され、他のインスタンスからの影響を受けにくくなるように設計されています。その結果、多テナントでのSLA(Service Level Agreement)運用や学習・推論の混在といった現場の課題に対して、安定性とスループットの両面で効果を発揮します。PCIe(PCI Express)上では独立デバイスとして扱えるため、重い処理が他のインスタンスをブロックしにくく、QoSが確保されます。
主なメリットは以下の通りです。
- 細粒度でのGPU資源の有効活用
- 論理分割による安全なマルチテナント運用
- 帯域の予約・隔離によるスループット安定化
セキュリティと帯域保証がされているのは、MIGのみだということがよく分かります。
| 技術 | 粒度 | 帯域保証 | セキュリティ | 対応GPU | 代表製品 |
|---|---|---|---|---|---|
| MPS※ | Thread | × | △ | Pascal+ | CUDA MPS |
| SR-IOV | PF/VF | △ | △ | NVIDIA A100+ | Virtio-GPU |
| vGPU | Frame | △ | △ | T4/A40 | NVIDIA vGPU |
| MIG | HW-SM | ◎ | ◎ | NVIDIA Ampere+ | NVIDIA A100/NVIDIA H100 NVL |
SR-IOV: Single Root I/O Virtualization
vGPU: Virtual GPU
3. マルチインスタンスGPU(MIG)の仕組み
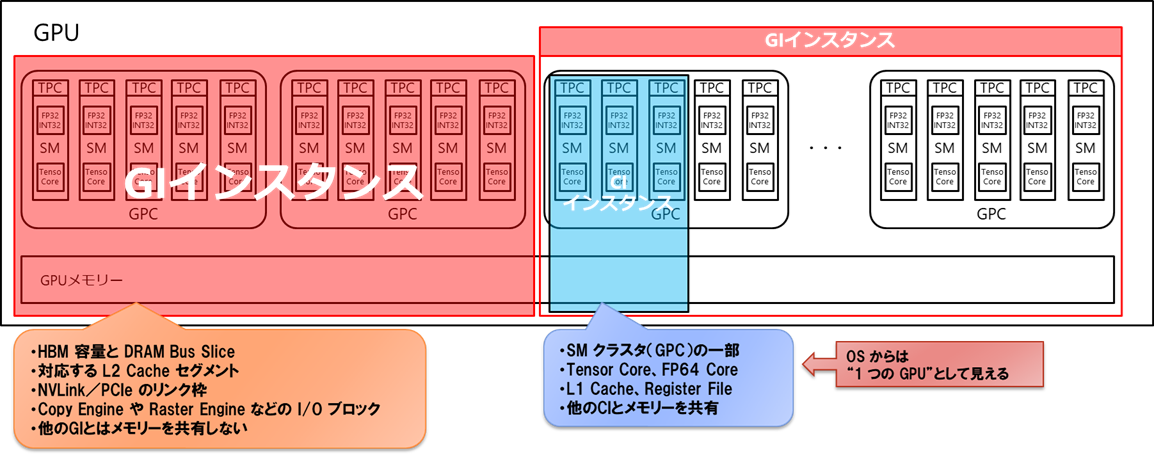
MIGの管理単位はアーキテクチャの世代で異なります。Ampere世代(NVIDIA A100)では、メモリ上限などの"外枠"を定めるGI(GPU Instance)の上に、演算資源の割り当てを定めるCI(Compute Instance)を作成する二段構成でした。一方、NVIDIA Hopper™世代(H100)以降では管理がシンプルになり、GIのみでインスタンスを扱います。
ハードウェアアーキテクチャの要点
- SM(Streaming Multiprocessor)、L2キャッシュ、HBM(High Bandwidth Memory)、Copy Engineを電気的に分割して干渉を排除
- DRAMバスをスライス単位で区切り、割り当て帯域を予約して保証
- NVIDIA NVLink™(NVIDIA高速インターコネクト)/PCIe帯域を静的仮想チャンネルで分配しI/O競合を抑制
4. 対応世代と設計上の注意
MIGはNVIDIA Ampere (A100)以降、NVIDIA Hopper(H100)、NVIDIA H200 NVLといった最新世代でサポートされます。設計上の注意点として、MIGを有効にした状態ではGPU間P2P(Peer-to-Peer、NVLink経由の直接通信)が非対応なので、分散学習でP2Pが必須な場合は、MIGを無効にしたフルGPU構成を別途用意するのが現実的です。
また、システム再起動時にはインスタンス構成が解除されるため、起動時の自動再構成手順を準備しておくと運用が安定します。インスタンス使用中は削除できない点にも留意が必要です。
Ampere(A100)とHopper(H100)の違い
| 項目 | Ampere MIG(A100) | Hopper MIG(H100) |
|---|---|---|
| 構成モデル | GI+CIの2段階 | GIのみ(CIは存在しない) |
| 分割単位 | GIがメモリを確保→その上でCIがSMを分割 | MIG作成時にメモリ+SMを一括確保 |
| 柔軟性 | 細かく調整できるが管理が複雑 | 単純化、運用容易 |
| 強化点 | 帯域QoS・暗号化の仕組みは限定的 | 帯域QoS・暗号化・セキュアMIG対応 |
5. プロファイル例と目安
下図はMIGでGPUを論理分割したイメージです。1g.18gbを2つ、1g.35gbを1つ、2g.35gbを1つの合計4つのインスタンスを作成しています。
▼MIG分割イメージ
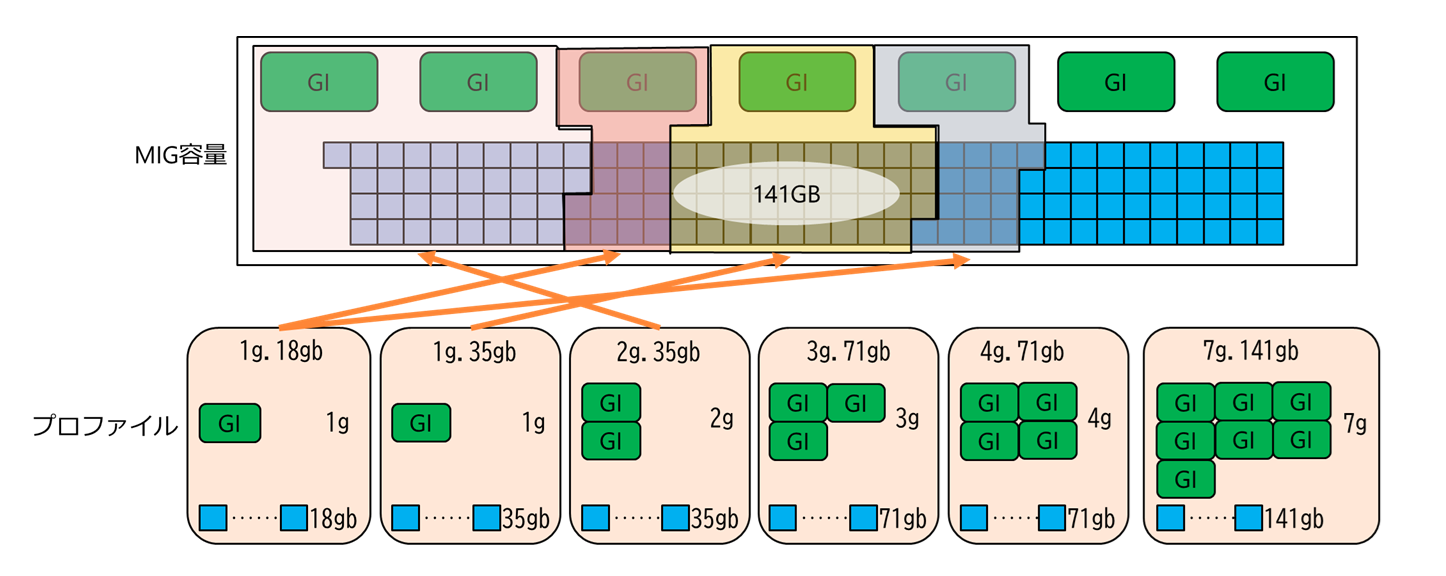
併せて、H200でのプロファイルを示します。
| Name | Prof. ID | Memory(GiB) | P2P | SM |
|---|---|---|---|---|
| 1g.18gb | 19 | 16.00 | No | 16 |
| 1g.35gb | 15 | 32.50 | No | 26 |
| 2g.35gb | 14 | 32.50 | No | 32 |
| 3g.71gb | 9 | 69.75 | No | 60 |
| 4g.71gb | 5 | 69.75 | No | 64 |
| 7g.141gb | 0 | 140.00 | No | 132 |
管理領域のオーバーヘッドにより、理論値と比較して実際に利用できるメモリは目減りする点に注意してください。
6. 実務手順(nvidia‑smi)
ここでは代表的な操作コマンドを示します。GPU/ドライバー世代により出力は一部異なります。6-1. プロファイルの確認
nvidia-smi mig -lgip6-2. マルチインスタンスGPU(MIG)の有効化/無効化
sudo nvidia-smi -i 0 -mig 1 # 有効化
sudo nvidia-smi -i 0 -mig 0 # 無効化6-3. 分割構成の適用(例)
sudo nvidia-smi mig -i 0 -cgi 14,14,19,15 -C
- プロファイルID
14(2g.35gb)×2個 - プロファイルID
19(1g.18gb)×1個 - プロファイルID
15(1g.35gb)×1個
-C オプションは、作成したGI(GPU Instance)に対して自動的にCI(Compute Instance)も作成します(Ampere世代の場合)。プロファイルIDは nvidia-smi mig -lgip で確認できます。
6-4. 構成の確認
nvidia-smi -L6-5. 作成済みインスタンスの一覧
sudo nvidia-smi mig -i 0 -lgi -lci6-6. インスタンスの削除(例)
sudo nvidia-smi mig -i 0 -dgi -gi <gi_id>6-7. lspciやデバイスファイルの見え方
- lspciの表示自体はMIG分割の有無で大きくは変わりません。
/dev/nvidia0..など基本デバイスはそのままですが、/dev/nvidia-caps等に追加デバイスが現れます。

$ ls -l /dev/nvidia-caps
cr-------- 1 root root 509, 1 Aug 21 12:32 nvidia-cap1
cr--r--r-- 1 root root 509, 2 Aug 21 12:32 nvidia-cap2
cr--r--r-- 1 root root 509, 435 Aug 25 16:01 nvidia-cap435
cr--r--r-- 1 root root 509, 436 Aug 25 16:01 nvidia-cap436
cr--r--r-- 1 root root 509, 453 Aug 25 16:01 nvidia-cap453
cr--r--r-- 1 root root 509, 454 Aug 25 16:01 nvidia-cap454
cr--r--r-- 1 root root 509, 489 Aug 25 16:01 nvidia-cap489
cr--r--r-- 1 root root 509, 490 Aug 25 16:01 nvidia-cap490
cr--r--r-- 1 root root 509, 525 Aug 25 16:01 nvidia-cap525
cr--r--r-- 1 root root 509, 526 Aug 25 16:01 nvidia-cap526上記のnvidia-capXを指定するか、nvidia-smi -Lで取得できる「MIG-」で始まるGPU UUIDを指定するかはアプリケーションの要件に応じて指定してください。
7. 運用と監視のポイント
MIG環境では、ジョブの可視化にGPU UUID(Universally Unique Identifier、一意識別子)の取り扱いが重要です。CUDA_VISIBLE_DEVICES や Docker の NVIDIA_VISIBLE_DEVICES にGPU UUIDを指定することで、意図したインスタンスのみをプロセスから見せることができます。監視には nvidia-smi に加えてDCGM(Data Center GPU Manager)の活用が有効です。プロファイルは頻繁に変えない運用の方がシンプルで、変更が多い場合は再構成の自動化(スクリプト化)を推奨します。分散学習でP2P/NVLinkを要するケースは、MIG無効の別構成を併用すると設計が明快です。
7-1. アプリ/コンテナからのマルチインスタンスGPU(MIG)指定方法
ホスト実行時はCUDA_VISIBLE_DEVICES にGPU UUIDを指定します。# 例: MIG デバイス UUID を 1 個だけ可視化
export CUDA_VISIBLE_DEVICES=MIG-c0a98019-719a-5ead-b4ae-42ccee90e676
python my_app.pyコンテナ実行時は
NVIDIA_VISIBLE_DEVICES でGPU UUIDを指定します。docker run --rm --gpus "device=MIG-c0a98...,MIG-bf0fe1..." \
-e NVIDIA_VISIBLE_DEVICES="MIG-c0a98...,MIG-bf0fe1..." \
myimage:latest7-2. 分割状況の確認例
nvidia-smi -L
# 出力例
GPU 0: NVIDIA H200 (UUID: GPU-0ec84c71-...)
MIG 2g.35gb Device 0: (UUID: MIG-f6ceaadd-...)
MIG 2g.35gb Device 1: (UUID: MIG-e452779f-...)
MIG 1g.18gb Device 2: (UUID: MIG-3a48416b-...)
MIG 1g.18gb Device 3: (UUID: MIG-b028b54b-...)8. よくある質問
Q. MIGの利用に追加ライセンスは必要ですか?A. MIG自体に追加費用は発生しません。ただし、アプリケーション側がGPU単位課金などのライセンス形態を採る場合はベンダー仕様に従います。
Q. 再起動後にUUIDは維持されますか?
A. 再起動でインスタンス構成は解除され、再構成後に新しいGPU UUIDが割り当てられます。起動時の自動再構成を準備しておくと運用が安定します。
9. まとめ
MIGは、厳密な隔離と高い資源効率を同時に満たす実装であり、多テナント運用やSLA(Service Level Agreement)、TCO(Total Cost of Ownership)最適化に向く有力な選択肢です。一方で、P2P/NVLink要件や再起動時の挙動など、設計段階で考慮すべき点もあります。ワークロードの通信要件と運用方針に応じて、MIG有効構成とフルGPU構成を適切に使い分けてください。筆者プロフィール

矢野 哲朗(やの てつろう)
株式会社スタイルズ(菱洋エレクトログループ会社)
経歴:Kubernetesを中心としたクラウドネイティブ基盤の構築・支援を専門とし、株式会社スタイルズでオープンソースを軸に20年以上インフラに携わる。
Edge/AI分野でのGPU活用にも注力中。
専門分野:Kubernetes/Rancherによるクラウドネイティブ基盤構築、GPUを活用したEdge・AI案件の技術支援など
現場で得た知見をもとに、クラウドネイティブやEdge/GPU/AI技術をわかりやすく解説します。
#Kubernetes #CloudNative #EdgeComputing #GPU #Rancher #Nextcloud




