

目次
1.はじめに
GPUトポロジーとは、複数のGPUを使った場合における物理的・論理的な接続構造のことを言います。近年では、大規模言語モデル(LLM)の学習や推論、科学技術計算など、複数のGPUを活用するワークロードが急速に増加しているため、GPU間のデータ転送速度と効率性はシステム全体のパフォーマンスに大きく影響します。特に分散学習では、GPU間で勾配情報を頻繁に交換する必要があるため、重要視されています。
2.主要な接続技術の比較
まず、複数のGPUを接続する技術についてどのようなものがあるかおさらいしましょう。主に以下の4つの接続技術があります。2-1.NVLink
NVIDIA NVLink™は、NVIDIA独自の高速GPU間接続技術です。
よくある勘違いとしては、複数のGPUを接続して画像演算を高速化するSLI(Scalable Link Interface)のようなものですか?と聞かれることがあります。SLIはGPU同士をSLIケーブルという特殊なケーブルで接続することにより、画像の演算領域を分担するという機能です。
しかし、NVLinkではそうではなく、GPU間でメモリー内容を直接コピーするための通信を担います。次で説明するPCIeよりも高速にGPUのメモリーからメモリーにデータを転送することを目的とした通信経路とプロトコルです。
最新のNVLink 4.0では、最大900GB/sという圧倒的な帯域幅(NVIDIA H200の場合)で、GPU間で低レイテンシーの直接通信(GPUDirect)が可能です。これにより、CPUやシステムメモリーを経由せずにGPU同士が直接データをやり取りできるため、通信オーバーヘッドを大幅に削減できます。
特にNVLinkはLLMの分散学習やテンソル並列処理、大規模な科学技術計算など、GPU間で大量のデータ交換が発生するワークロードにおいて威力を発揮します。NVIDIA DGX™システムなどのハイエンド構成では、NVLink Switchを介してすべてのGPUがフルメッシュで接続され、All-to-All通信が最適化されています。
2-2.PCIe
PCIe(PCI Express)は、従来から広く使用されている汎用接続規格です。CPUや周辺機器との接続のために考え出されたバス接続規格で汎用性が求められます。
最新のPCIe 5.0では、x16の時に最大128GB/s(片方向64GB/s)の帯域幅を提供しますが、NVLinkと比較すると約7分の1程度です。しかし、PCIeは汎用性が高く、GPUだけでなくストレージやネットワークカードなど、さまざまなデバイスに対応できる点が強みとなっています。
コスト面でも、PCIeベースのシステムはNVLink対応システムと比べて導入コストが抑えられるため、小規模なマルチGPU構成や、GPU間通信がボトルネックにならないワークロードでは十分な選択肢となります。
PCIeについて詳しく知りたい方は以下の記事をご覧ください。
参考:PCI Expressとは | 第1回 - PCI Expressについて 入門編|エンジニアによりそう、リョーサンのマガジンサイト|リョーサンテクラボ|株式会社リョーサン(RYOSAN)
※外部リンクに飛びます
2-3.NUMA Interconnect
一方、現在のサーバーは複数のCPUソケット持つサーバーが当たり前になっています。そうなるとCPUとCPUも接続する必要があり、NUMA(Non-Uniform Memory Access)Interconnectという技術も必要になっています。NUMA Interconnectは、複数のCPUソケット間を接続します。マルチソケットサーバーでは、各CPUが独自のメモリー空間を持ちますが、NUMA Interconnectを介して他のCPUのメモリーにもアクセスできるようになります。2-4. PCIeスイッチ
多数のPCIeデバイスを接続する際には、1つのPCIeルートポートを複数デバイスに分岐する「PCIeスイッチ」を用います。PCIeスイッチは、1つのPCIeルートポート(通常はCPUから提供される)を複数のPCIeデバイスに分岐させるためのハードウェアです。CPUが提供するPCIeレーン数には限りがあるため、多数のGPUやその他のPCIeデバイスを接続する場合には、PCIeスイッチが必要になります。PCIeスイッチについて詳しく知りたい方は以下の記事をご覧ください。
参考:拡張性とマルチホスト | 第2回 - PCI Expressについて 入門編|エンジニアによりそう、リョーサンのマガジンサイト|リョーサンテクラボ|株式会社リョーサン(RYOSAN)
※外部リンクに飛びます
3.NVLinkとPCIeの接合部の課題
実はNVLinkってスゴイ素晴らしい!というだけでは解決できない課題があります。NVLinkはあくまで複数のGPU間を繋ぐだけであり、GPU以外のデバイスに繋ぐには結局PCIeバスに頼る必要があります。また、CPUが接続できるPCIeバスにも限りがあり、複数のCPUがある場合にはNUMA Interconnect経由でなければ接続できないデバイスも出てきます。NVLinkにネットワークインターフェースカードを繋げたり、ストレージアダプターを直接繋げたりすることはできないのです。つまりマルチGPU環境では、これら4つの接続技術が組み合わさって、通信する経路が重要になります。これらの接続技術の特性を理解し、ワークロードに応じた最適な構成と経路を選択することが、システムパフォーマンスを最大化する鍵となります。
- NVLink:GPU間の高速専用接続(最大900GB/s)、高価だが高性能
- PCIe:GPU-CPU間やその他デバイスとの汎用接続(最大128GB/s)、低コストで汎用性が高い
- NUMA Interconnect:マルチソケット環境でのCPU間接続、GPUの配置最適化に影響
- PCIeスイッチ:限られたPCIeレーンを複数デバイスに分岐、帯域幅の共有に注意が必要
4.実践的な考察
上記の4つの技術を理解した上で、トポロジーの確認方法について解説します。4-1.トポロジーの確認方法
まず、実際のシステムでGPUトポロジーを確認するには、nvidia-smi topo-mコマンドを使います。このコマンドを実行すると、GPU間の接続方式(NVLink、PCIe)や接続数が表形式で表示され、システムのトポロジーを一目で把握できます。また、nvtopなどのモニタリングツールを使用すれば、リアルタイムでGPU間の通信状況を監視することも可能です。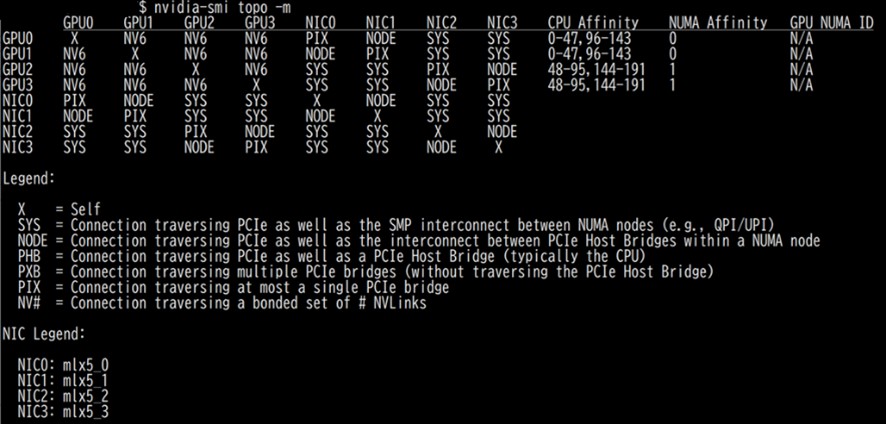
4-2.nvidia-smi topo-mコマンド解説
上記のコマンドを実行したサーバーは、NVIDIA H200が4枚、MellanoxのConnectX-7 InfiniBand HCAが2枚搭載されています。そのため、GPU0からGPU3およびNIC0からNIC3まで表示されています。上半分のマトリックスがGPUとNICとの接続を示しています。マトリックスの右の方にあるCPU AffinityとNUMA Affinityが、GPUが接続しているCPUを示しています。このサーバーは2ソケット構成なのでNUMAは0と1です。
下半分のLegendとNIC Legendは、Legendがマトリックスのそれぞれのデバイスの接続方法を示しています。6つの接続経路がある事が分かります。
それぞれの接続経路の簡単な説明を以下に挙げます。上にあるものほど近く、下に行くほど遠い接続を表します。
| 略語 | 意味 | 典型的な通信経路 | 通信距離の目安 |
|---|---|---|---|
| NV# | 指定された本数(#)のNVLinkでGPU同士が直結 | GPU間(NVLink) | 最も近い |
| PIX | 1つのPCIeブリッジのみを経由 | PCIe直結(単一ブリッジ) | 近い |
| PXB | 複数のPCIeブリッジを経由 (PCIeホストブリッジは経由しない) |
複数ブリッジ(CPUは経由しない) | やや近い |
| PHB | PCIeホストブリッジ(通常はCPU)を経由 | CPU直結のデバイス同士 | やや遠い |
| NODE | PCIe内の異なるホストブリッジ間を経由 (同一NUMAノード内) |
同一NUMA、異PCIeホストブリッジ | 遠い |
| SYS | PCIeおよびNUMAノード間のインターコネクト (例: UPI(旧称QPI))を経由 |
NUMAノード間(複数CPU間) | 最も遠い |
4-3.GPU0からの各デバイスへの接続経路
各デバイスへの接続経路について、GPU0を起点にみてみます。 図としては以下のようになります。▼GPU0からみた各デバイス接続図
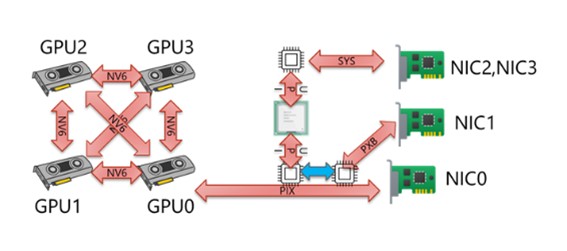
4-4. パフォーマンスへの影響
これらのトポロジーの違いは、実際のワークロードのパフォーマンスに影響を与えます。例えば、データ並列処理では各イテレーション後にGPU間で勾配の同期が必要となり、この通信時間がトレーニング速度を左右します。NVLinkを使用した場合、PCIeと比較して通信時間を60~80%程度削減できるケースもあります。また、通信経路でNIC2やNIC3を使った通信はNVLinkの帯域の数分の1になることもあります。一方、各GPUが独立してバッチ処理を行う場合や、GPU間通信が少ないワークロードでは、PCIeでも十分なパフォーマンスが得られます。重要なのは、ワークロードの特性を理解し、通信パターンに応じた適切なトポロジーを選択することです。
5.まとめ
GPUトポロジーの選択は、システムのパフォーマンスとコストのバランスを決定する重要な要素です。大規模な分散学習やHPCなど、GPU間通信が頻繁に発生するワークロードではNVLinkの採用が推奨されますが、通信量が限定的な場合はPCIeベースの構成でも十分な性能が得られます。今後、AI/機械学習のモデルサイズがさらに拡大していく中で、GPU間接続技術の重要性は一層高まっていくでしょう。NVLink 5.0やNVLink Fusion、UCIe(Universal Chiplet Interconnect Express)など、次世代の接続技術にも注目が集まっています。自社のワークロードに最適なトポロジーを見極め、投資対効果を最大化することが、これからのGPUインフラ構築の鍵となるでしょう。
参考リンク:
-[Kubernetes公式サイト] ※外部リンクに飛びます
-[SUSE Kubernetes] ※外部リンクに飛びます
-[Kubernetesとは?初心者向けに分かりやすく解説]
-[Rancherとは?初心者向けに分かりやすく解説]
筆者プロフィール

矢野 哲朗(やの てつろう)
株式会社スタイルズ(菱洋エレクトログループ会社)
経歴:Kubernetesを中心としたクラウドネイティブ基盤の構築・支援を専門とし、株式会社スタイルズでオープンソースを軸に20年以上インフラに携わる。
Edge/AI分野でのGPU活用にも注力中。
専門分野:Kubernetes/Rancherによるクラウドネイティブ基盤構築、GPUを活用したEdge・AI案件の技術支援など
現場で得た知見をもとに、クラウドネイティブやEdge/GPU/AI技術をわかりやすく解説します。
#Kubernetes #CloudNative #EdgeComputing #GPU #Rancher #Nextcloud
公開日:
最終更新日:




