

目次
AIを利用するインフラストラクチャを効率なものにしたいと考えている人も多いかと思います。現在はKubernetesなどのコンテナでインフラ運用することが標準的になってきておりますが、GPUを活用したAIワークロードや高速ネットワークを必要とするHPC/生成AIでは、導入・運用のハードルが依然として高いのが現実です。例えば、現状の以下のような問題点がAIインフラにおいて課題となっていると思われます。
- GPUドライバの管理やアップデート
- RDMA/InfiniBandの複雑な設定
- 推論マイクロサービスの継続運用とスケジューリング
1.Kubernetes環境での展開と管理を簡素化
Kubernetes環境全体でオペレーションの展開および管理を容易にするため、GPU Operator、Network Operator、およびNVIDIA NIM™ Operatorが用意されています。これらのOperatorにより、GPUパフォーマンスの最適化やテレメトリ機能を含む高度な機能を利用することができ、開発者はアプリケーションの開発に専念できるので、Kubernetesの運用から解放されます。
NVIDIA Network Operatorは、Kubernetesでのスケーラブルなネットワーク設計を簡素化するため、高速化ネットワーキングに必要なソフトウェアの展開と構成を自動化します。また、GPU OperatorとNetwork Operatorは、クラウドネイティブのAIワークロードを数倍高速化するキーテクノロジーであるNVIDIA GPU Direct RDMAを可能にします。
NVIDIA NIM Operatorは、Kubernetes上でNVIDIA NIM マイクロサービスで構築された生成AIアプリケーションの展開とライフサイクル管理を自動化します。
NIM Operatorは、ユーザーがエンドツーエンドのAIアプリケーションの開発・運用(MLOps)に集中できるようになります。
▼図1 Kubernetes上での展開と管理の簡素化
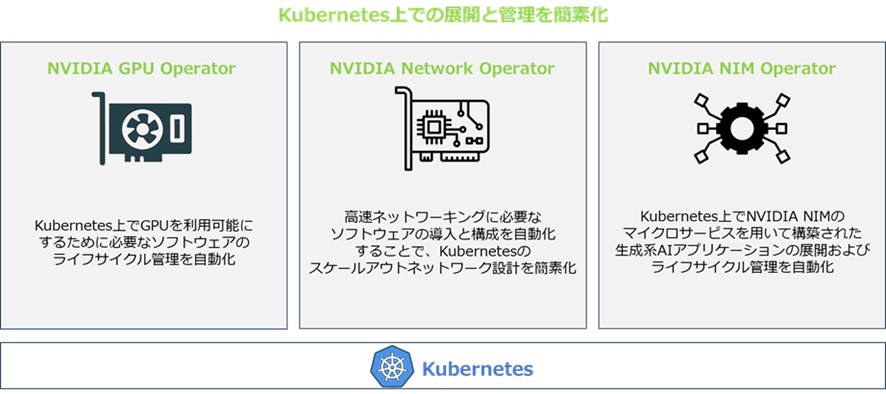
これにより、ユーザーはKubernetes上でAIを迅速かつ確実に本番展開し、ビジネス価値の創出に専念できるようになります。
各Operatorの役割を以下にまとめます。
| オペレーター種別 | 主な役割 | 効果 |
|---|---|---|
| GPU Operator | GPUの導入と管理の自動化 | AIアプリ開発に集中できる環境を実現 |
| Network Operator | 高速ネットワークの構築自動化(RDMA) | AI処理速度を大幅に向上 |
| NIM Operator | 生成AIアプリのデプロイと管理を自動化 | MLOps効率化・エンドツーエンド開発に集中可能 |
2.GPUを利用するKubernetesクラスタはどのようなものなのか?
GPU Operatorの価値を理解するために、GPUを搭載したKubernetesクラスタ構造をご説明します。下図の左側にクラスタのコントロール(制御)プレーンがあります。これには、クラスタの状態を維持するAPIサーバー、etcdキーバリューストアなどのコンポーネントが含まれます。
ユーザーはコントロールプレーンを通じてクラスタを操作・問い合わせすることで、通常はKubernetesリソースの作成や情報の取得にkubectlコマンドユーティリティを使用します。
そして下図の右側にはクラスタ内の一般的なノードがあります。ここにはGPUを実行する際に必要なコンポーネントが含まれています。コンテナランタイムはNVIDIA拡張機能(コンテナツールキットなど)と組み合わせて、そのランタイム環境でGPUを有効化します。
さらに、ノード上で検出された利用可能なGPUを通知することで、ノードエージェントであるKubeletと連携するデバイスプラグインがあります。その情報がコントロールプレーンに渡されることで、スケジューラーはGPU対応ポッドをどのノードに配置するかを適切に決定できます。緑色の部分はKubernetesでNVIDIA GPUを利用するために必要な最小限のソフトウェアを意味します。
それらのソフトウェアは個々のコンテナとして提供されており、ユーザーは独自の自動化ツールを構築して、これらのコンポーネントのインストールとライフサイクル管理を行うことができます。
▼Kubernetesクラスタの構成要素
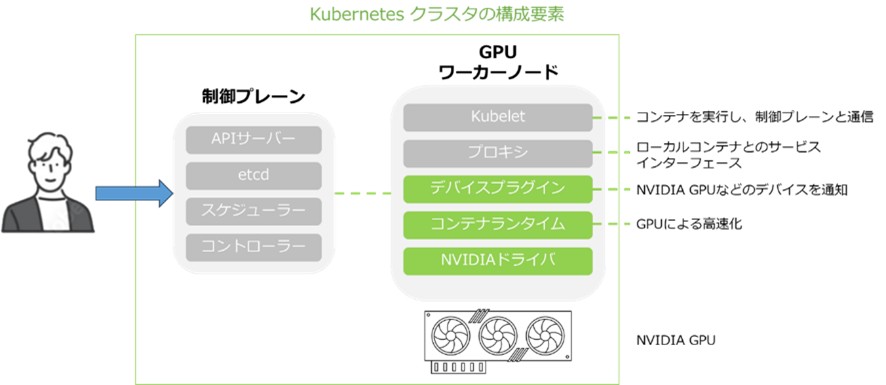
これらを導入することにより、コンポーネント間の互換性、アップグレード、スケーリング、本番環境でのバグ修正の適用などで、これらのコンポーネントのライフサイクル管理を容易に行うことができます。
3.GPU Operatorとは?
NVIDIA GPU Operatorは、インフラチームがKubernetes上でGPUを利用するために必要なすべてを提供するオープンソースソフトウェアで、Kubernetesクラスタ内のGPUデバイスを含む任意のノード上でGPUに必要なすべてのNVIDIAソフトウェアの展開と管理を自動化することで実現されます。これにより、GPUで高速化されたアプリケーションをKubernetes上でスケールアップする際の時間を短縮し、エラーのない自動化プロセスを実現できます。
GPU Operatorは、クラスタの現在の状態を監視し、理想の状態に自動調整する「オペレーターフレームワーク」に基づいて構築されており、例えばドライババージョンの一括変更も1行のポリシーで済みます。
また、NVIDIAにはスマートNIC環境を同様に自動化するNetwork Operatorもあり、GPU Operatorと組み合わせることでKubernetes上でのAI/HPC基盤をシンプルに運用できます。
▼図3 GPU Operator概念図

GPU Operatorにより、Kubernetes上でのGPUとネットワークの運用は驚くほどシンプルになり、インフラ管理から解放されてAIやHPC価値創出に専念できるようになります。
4.KubernetesでGPUのパワーを引き出す
Kubernetesは、ディープラーニングの商用展開に欠かせない基盤ですが、GPUなしでは実用的なAIモデルの開発は困難です。そこでNVIDIA GPU Operatorが、Helmチャートを用いたシンプルなデプロイで、Kubernetesクラスタに必要なGPUソフトウェアを自動インストールし、運用を劇的に簡素化します。
また、新たなGPUノードも自動検出して設定、ローリングアップグレードでダウンタイムを抑えた更新、さらにGPU Direct RDMAやMIGといった高度機能の有効化まで自動化します。
GPU OperatorはNetwork Operatorと連携し、GPU Direct技術を最大限に活用しながら、DCGMによるGPUテレメトリ監視で最適化まで支援します。
▼図4 GPU Operatorを導入するメリット
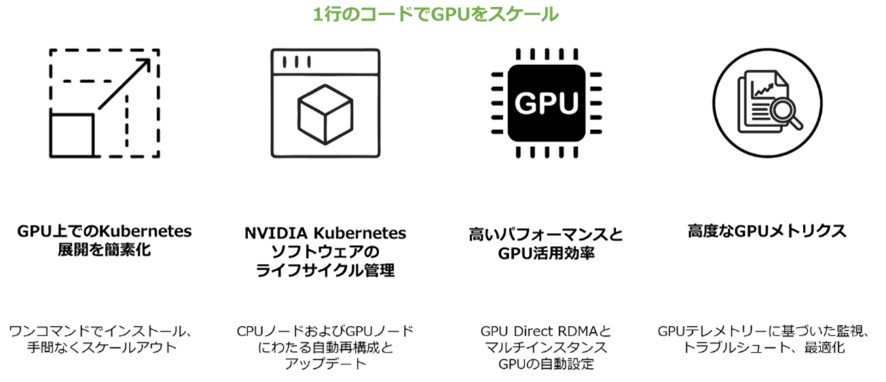
こうして、Kubernetes上でのGPU活用はよりシンプルかつ強力になり、AIの価値創出に集中できるようになります。
5.GPU Operatorのデプロイ
NVIDIA GPU Operatorは、単一コマンドで簡単に導入でき、GPUを搭載したKubernetesノードを自動検出して必要なソフトウェアを自動デプロイします。これにより追加作業なしでGPU高速化アプリケーションを稼働可能にし、GPUを持たないノードには何も適用されないため、CPU・GPU混在環境も安心です。
また、新たに追加されたGPUノードも自動検出し、ゼロタッチでスケールアウトできます。NFD(Node Feature Discovery)によりGPUハードウェアを認識し、ノードに適切なラベルを付与することで、自動展開を実現します。
▼図5 GPU Operatorのデプロイ方法
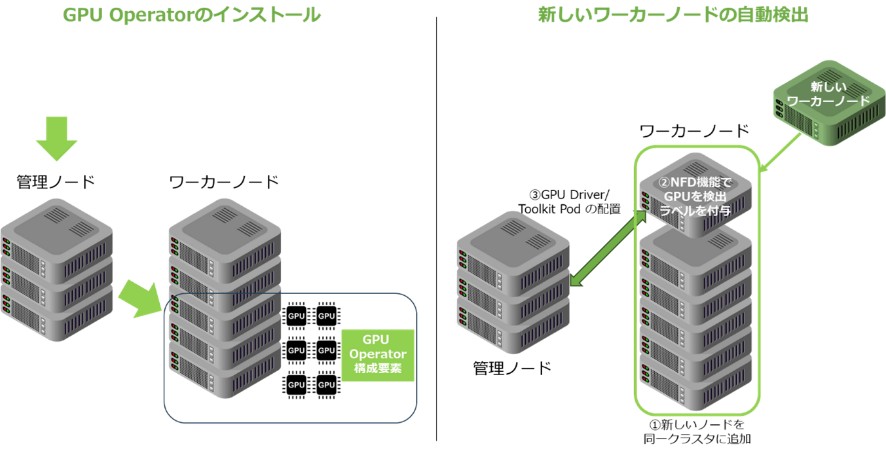
詳細なインストール手順については、こちらをご参照ください。
6.GPU Operatorのエコシステム
GPU Operatorは、幅広い環境に対応します。UbuntuやRHEL、RHCOSといった主要OS上で動作し、Docker Engine、CRI-Oなどのコンテナランタイムをサポートします。また、Kubernetes ディストリビューションにも対応しています。VMware TanzuやGoogle Kubernetes Engine(GKE)、Amazon EKS、Azure Kubernetes Services(AKS)などクラウドのフルマネージドKubernetesにも対応しており、オンプレミスからクラウドまで一貫した運用が可能です。
▼図6 GPU Operatorのエコシステム

これにより、あらゆる環境でGPUを活用したAIワークロードを安心して展開できる柔軟な基盤が整います。
サポートされているプラットフォームの詳細は、こちらをご参照ください。
7.NVIDIA AI Enterpriseによるサポート
GPU Operatorは、オープンソースでNGCから無料で利用可能ですが、多くの企業は本番環境でのトラブル時にNVIDIAの商用サポートを求めています。NVIDIAは、GPU Operatorを含むAI&データ分析向けクラウドネイティブソフトウェアスイート「NVIDIA AI Enterprise」を提供しています。これにより、認定済みのシステムでの運用およびNGCプライベートリポジトリへのアクセス、さらにvSphere向けのvGPUドライバコンテナなどを活用し、安心してAI基盤を展開できます。
▼図7 NVIDIA NGC™ カタログ

8. まとめ
GPU Operatorについて説明してきましたが、GPU Operatorを利用することで、Kubernetes上でGPUを活用するために必要な全てのソフトウェアを自動でインストールし、そのライフサイクルを管理できます。また、インフラチームは複雑な構成やアップデート作業から解放され、GPU高速化アプリケーションのスケーラブルな展開が容易になります。
主なポイントとしては、以下の通りです。
- ワンコマンド導入&自動スケール
たった1行のコードでGPU Operatorを導入可能。GPU搭載ノードを自動で検出し、必要なNVIDIAソフトウェアをデプロイします。 - GPUの高度な活用を自動化
GPU Direct RDMAやマルチインスタンスGPU(MIG)の自動設定、GPUテレメトリに基づく監視やトラブルシュートをサポート。 - アップデートも安心
ローリングアップグレードにより、ダウンタイムを最小限に抑えた更新が可能です。 - CPUノードとのハイブリッド環境にも対応
GPUが載っていないノードは変更されず、GPUとCPUが混在するKubernetesクラスタでもそのまま利用できます。
GPUの性能を最大限に引き出しながら、インフラ運用をシンプルにし、AIの価値創出に専念できる環境を構築しましょう!
関連記事はこちら:
- [Kubernetesとは?初心者向けに分かりやすく解説]
- [NVIDIA AI Enterpriseのソフトウェアおよびインフラストラクチャについて]
筆者プロフィール

小宮 敏博(こみや としひろ)
菱洋エレクトロ株式会社|ソリューション事業本部 ソリューション技術部 営業技術G
経歴:KDDIで約8年システムエンジニアを経験後、ストレージベンダー・ソフトウェアベンダー・サーバーベンダーにてプリセールス、仮想化ソリューション、HCIビジネスの事業開発に従事。
2022年から株式会社トゥモロー・ネットにてセールスエンジニアリング部門長およびソリューション/AIビジネス開発に従事。主にNVIDIA 商材を取り扱っていた。
2025年からは現職。菱洋での実績は・・・NVIDIA AI EnterpriseとNVIDIA DGX Spark™をやっています!
専門分野:仮想化(VMware / Nutanix)関連、NVIDIA AI Enterprise / DGX Spark / LLM推論 / AIインフラ(Cuda / Docker / Kubernetes / その他)など
現場目線で、GPU×生成AIの実務ノウハウをわかりやすく発信します。
#NVIDIA #nvidiaaienterprise #LLM推論 #dgxspark #GPU #aiblog
公開日:
最終更新日:





