productNVIDIA
A100 Tensor Core GPU 80GB(販売終了製品)
あらゆるスケールでの前例のない高速化を実現
A100 Tensor Core GPU 80GB

NVIDIA A100 Tensor Core GPU 80GBは、NVIDIA Ampereアーキテクチャを採用し80GBの大容量メモリーを搭載したデータセンター向けGPUです。
特長
あらゆる規模で前例のない加速
NVIDIA A100 TensorコアGPUは、NVIDIA Ampereアーキテクチャを採用し、AI、データ分析、およびHPCのあらゆる場面で前例のない加速を提供し、世界で最も困難なコンピューティングの課題に挑戦できます。A100の第3世代のTensorコアテクノロジーは、多様なワークロードを高いレベルの精度で加速し、学習結果と市場投入までの時間を短縮します。
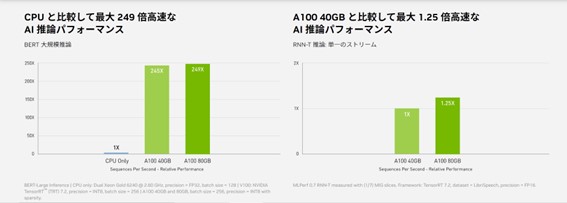
新たなデータフォーマットをサポート
NVIDIA A100の第3世代TensorコアとTensor Float(TF32)精度を利用することで、前世代と比較して最大20倍のパフォーマンスがコードを変更することなく得られます。また、Automatic Mixed Precision(AMP)と FP16の活用でさらに2倍の高速化が可能になります。
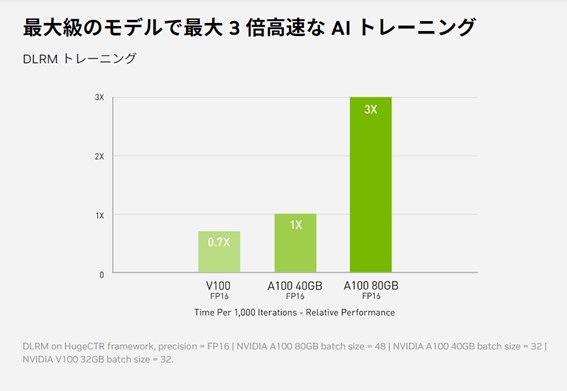
ディープラーニング レコメンデーション モデル(DLRM)といった大きなデータテーブルを持つ最大級のモデルの場合、A100 80GBであれば、ノードあたり最大1.3TBの統合メモリーに到達し、A100 40GBの最大3倍のスループットの増加が可能です。
マルチインスタンスGPU(MIG)機能追加
第3世代のNVIDIA Tensorコアにより性能を大幅に向上できるようになり、さらに、新たに追加されたMIG(マルチインスタンス GPU)機能は、A100 GPUを7つのインスタンスに分割して、メモリー、キャッシュ、コンピューティングコアなどのリソースを割り当てて利用できることにより、演算要求の異なる様々な処理に最適な演算性能を提供します。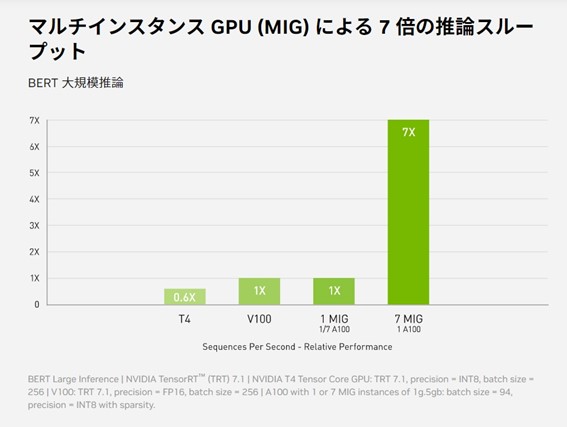
MIGは、Kubernetes、コンテナー、ハイパーバイザーベースのサーバー仮想化と連動します。MIGを利用することで、インフラストラクチャ管理者はあらゆるジョブに適切なサイズのGPUを提供し、サービスの品質(QoS)を保証できます。
製品情報
| 製品名 | NVIDIA A100 Tensor Core GPU 80GB |
| 型番 | NVA100-80G |
| JANコード | なし |
| 価格 | オープンプライス |
| 同梱物 | 保証書 補助ケーブル(CPU8Pin to PCIe8Pin Powerアダプター) |
仕様
| 項目 | 内容 |
|---|---|
| アーキテクチャ | Ampere |
| GPUメモリー | 80GB HBM2e |
| メモリー帯域幅 | 1,935GB/s |
| エラー修正コード(ECC) | 対応 |
| FP64 | 9.7TFLOPS |
| FP64 Tensor Core | 19.5TFLOPS |
| FP32 | 19.5TFLOPS |
| TF32 Tensor Core | 156TFLOPS/312TFLOPS* |
| BFLOAT16 Tensor core | 312TFLOPS/624TFLOPS* |
| INT8 Tensor Core | 624TOPS/1,248TOPS* |
| NVIDIA NVLINK | 対応 |
| インターコネクト | PCle4.0:64GB/s 第3世代NVLink:600GB/s (2GPUでのNVLink Bridge利用時) |
| 冷却機構 | パッシブ |
| フォームファクター(mm) | 高さ111.76x長さ266.7 Dual Slot |
| マルチインスタンスGPU(MIG) | 最大7GPU |
| 消費電力 | 300W |
| コンピュートAPI | CUDA DirectCompute OpenCL OpenACC |
| 同梱物 | 保証書 補助ケーブル(CPU8Pin to PCIe8Pin Powerアダプター) |
*sparsity有効時
オプション/保証
<オプション>  |
 |
| 製品名 | NVLINK For Ampere 2-SLOT Retail NVLINK For Ampere 3-SLOT Retail |
| 型番 | NVLINK FOR AMPERE 2S RETAIL NVLINK FOR AMPERE 3S RETAIL |
<製品保証>
保証対象製品の交換(センドバック方式)
※ ユーザー起因はこの限りではありません
※ 交換後の保証期間は、元の保証期間の残存期間が適用されます
※ 仕様などは予告なしに変更されることがあります
外観
 |
 |
 |
 |
関連製品



